
Déployer et variabiliser une Azure Data Factory (ADF) sur différents environnements en exportant son template ARM peut vite devenir fastidieux. D’autant plus quand le nombre de flux à exporter augmente. On a potentiellement des centaines de pipelines et de datasets qui rendent vite les ARMs complexes, difficilement lisibles et manipulables.
A l’inverse, il est possible de tout automatiser ou presque, pour gérer plusieurs ADFs dans divers environnements sans avoir à manipuler aucun template ARM. A la fin de cet article, un simple pipeline de déploiement sur Azure DevOps sera suffisant pour gérer la mise à jour et le déploiement de vos ADFs depuis l’environnement de développement jusqu’à celui de production.
La première chose à faire est de connecter l’ADF de développement à GIT. Pour cela sélectionnez l’ADF concerné dans le portail Azure, puis sélectionnez « Author & Monitor ».
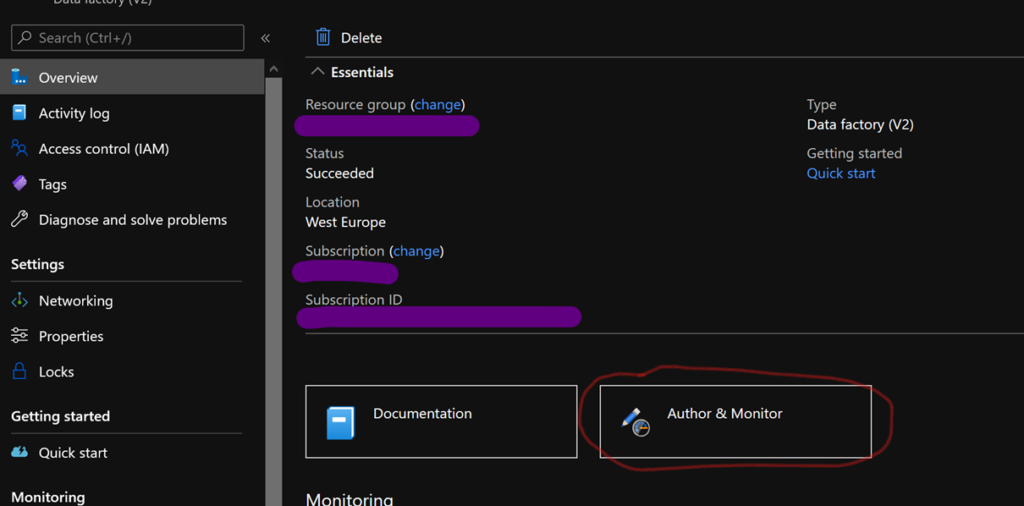
L’interface de l’ADF s’ouvre, dans l’onglet « Author » cliquez sur le menu déroulant « Data Factory », puis sur « Set up code repository ».
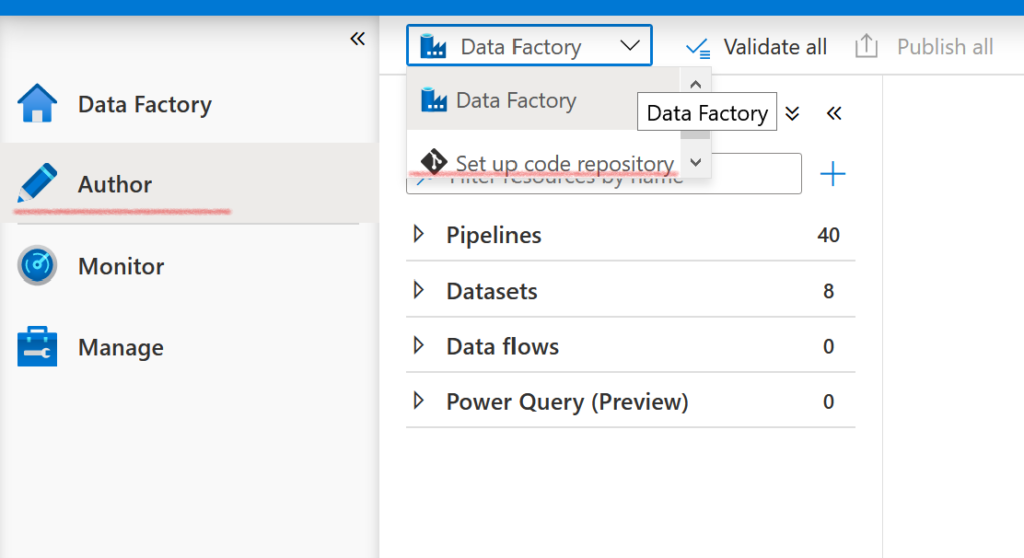
Il faut ensuite associer notre ADF à un GIT disponible sur Azure DevOps. Vous pouvez choisir de créer un nouveau répertoire ou d’en utiliser un existant. Dans tous les cas, on note qu’ADF utilisera deux branches différentes, master et adf_publish dans cet exemple. La première contiendra les ARMs à jour, avec un fichier par pipeline, dataset, data flow… La seconde génèrera un ARM complet de l’ADF et de tous ses composants déjà variabilisés ! C’est de cette branche dont on va se servir pour déployer en automatique nos ADFs.
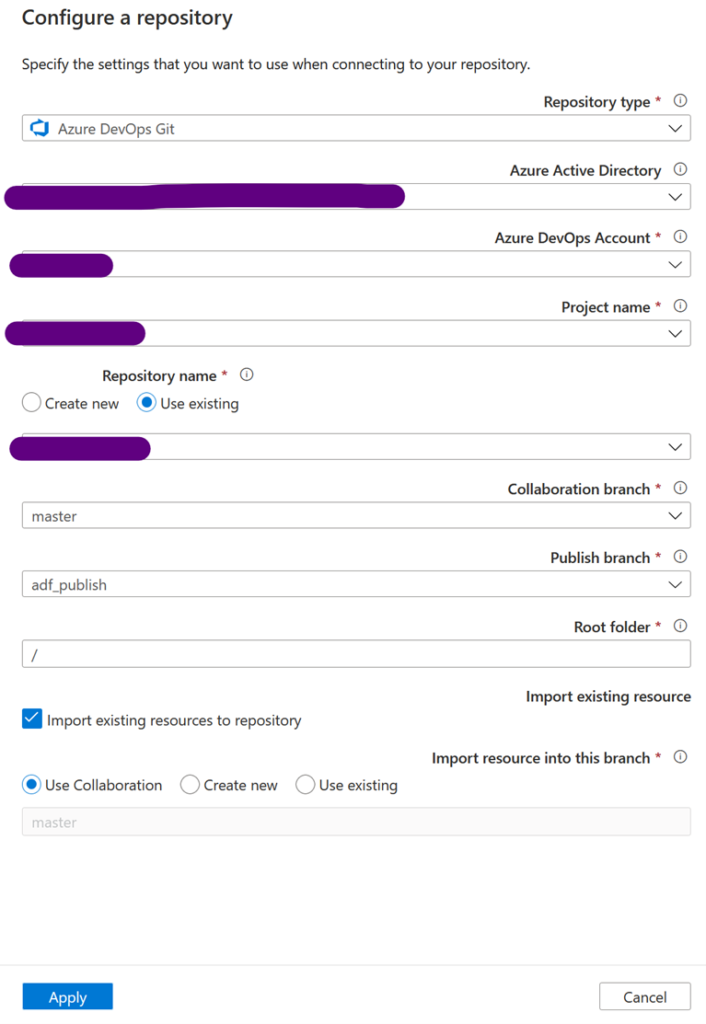
A noter : vous pouvez travailler sur d’autres branches, mais seul le code publié depuis la branche master sera déployé sur l’ADF de développement et sera automatiquement généré dans la branche adf_publish.
Plus précisément, lorsque vous travaillez sur la branche master, chaque nouvelle sauvegarde sera stockée sur GIT, mais seules les publications entraîneront la génération d’un nouvel ARM complet de l’ADF sur adf_publish.
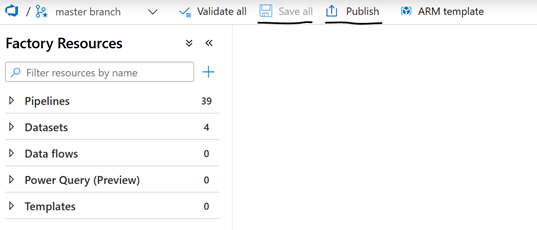
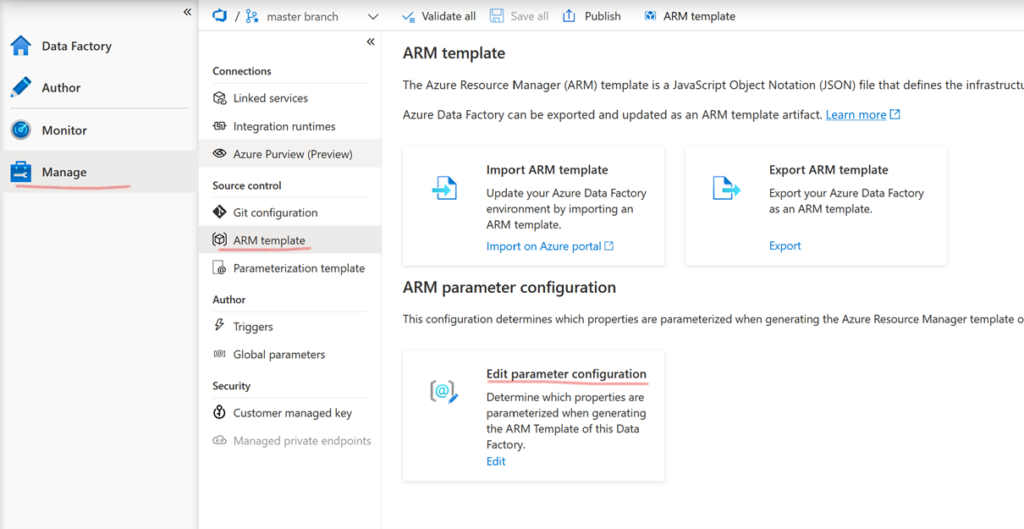
Si ce template est automatiquement variabilisé, il est possible de contrôler plus finement la façon dont il l’est. Dans cet article, on va utiliser la variabilisation par défaut. Mais sachez que si vous le désirez, vous pouvez modifier la génération en allant dans l’onglet « Manage », puis « ARM template », puis « Edit parameter configuration ». Plus d’information ici.
Par la suite, on va se servir de secrets contenus dans des keyvaults pour automatiser au maximum l’intégration continue puis le déploiement de nos ADFs. Pour cela, il est nécessaire d’autoriser les ADFs à accéder aux keyvault dont elles ont besoin.
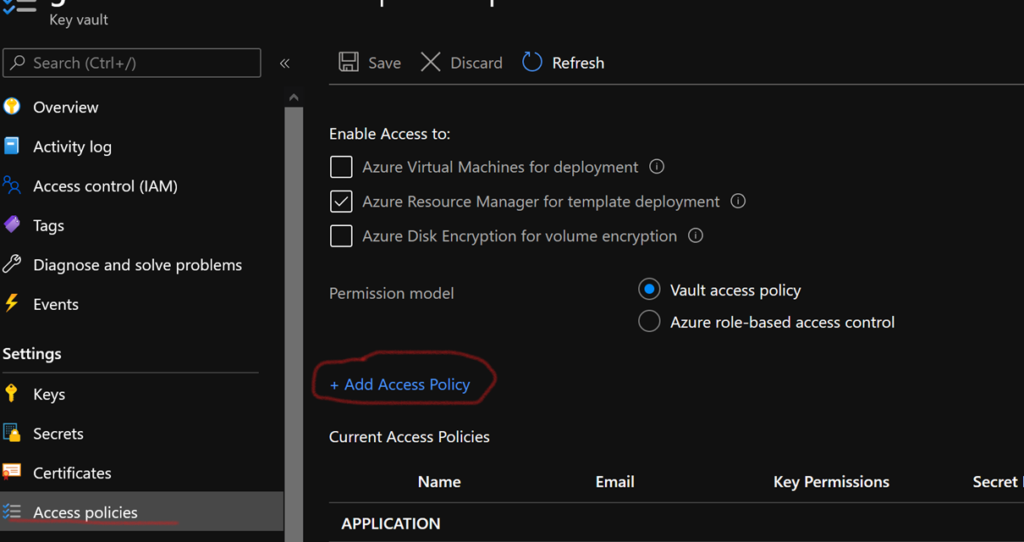
Vous pouvez autoriser manuellement un ADF à accéder à un keyvault. Pour cela, depuis l’interface du keyvault, sélectionnez « Access policies », puis « Add Access Policy ». Dans « Secret permissions » cochez Get et List. Puis en cliquant sur select principal, une liste déroulante s’ouvre, retrouvez votre ADF et ajoutez la nouvelle policy. Maintenant, votre ADF peut accéder aux secrets stockés dans le keyvault !
Toutefois dans une démarche de déploiement continue, le mieux est de scripter les droits d’accès aux keyvaults pour vos ADFs. Pour cela, on peut ajouter le code suivant au template ARM du keyvault dans le bloc « accessPolicies » :
"accessPolicies": [
{
"tenantId": "[subscription().tenantid]",
"objectId": "[parameters('adf_object_id')]",
"permissions": {
"keys": [], ],
"secrets": [
"Get",
"List"
],
"certificates": []
}
}
]
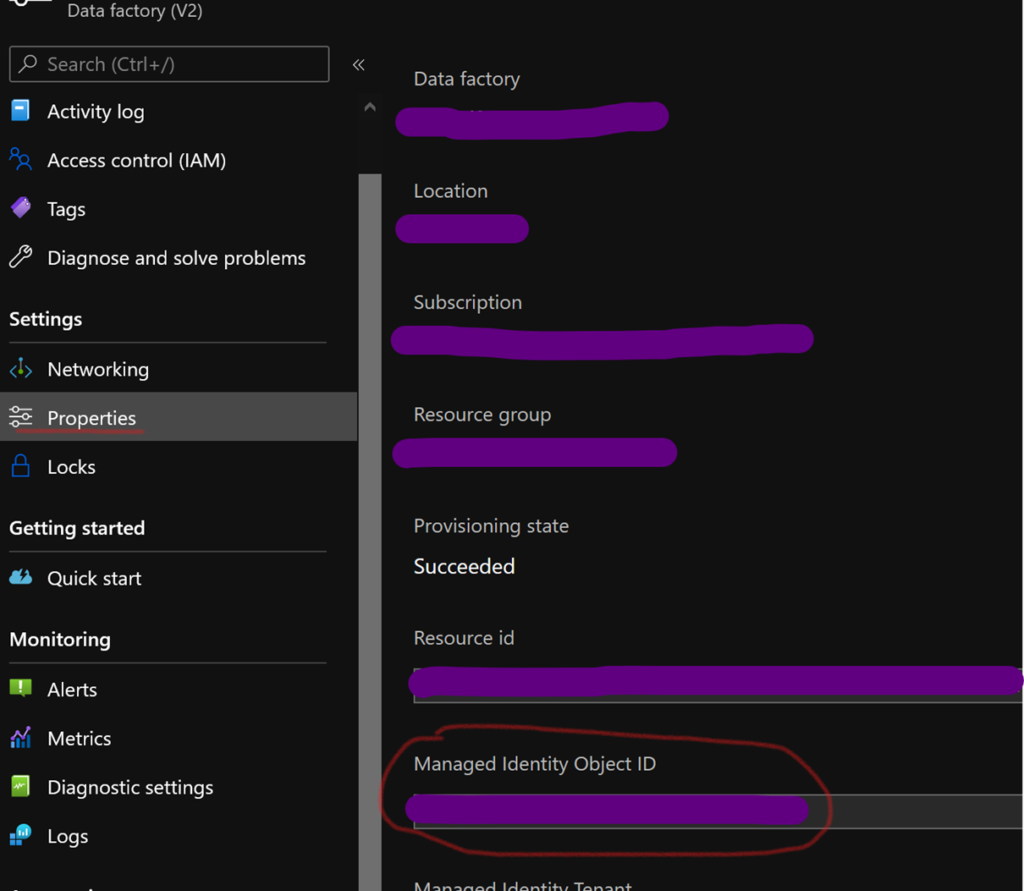
« [parameters(‘adf_object_id’)] » correspond à l’object id de votre ADF, vous pouvez le retrouver dans le volet « Properties » d’un ADF, au niveau de « Managed Identity Object ID ». On le déclare en tant que paramètre de l’ARM pour essayer de réutiliser au maximum nos ARMs de keyvaults sur nos les différents environnements.
Pour profiter au maximum de la génération automatique des ARMs de notre ADF de développement, on va utiliser une démarche simple : toujours passer par une URL ou un secret pour paramétrer un dataset. En effet, ceux-ci sont variabilisés par défaut lors de la génération des ARMs.
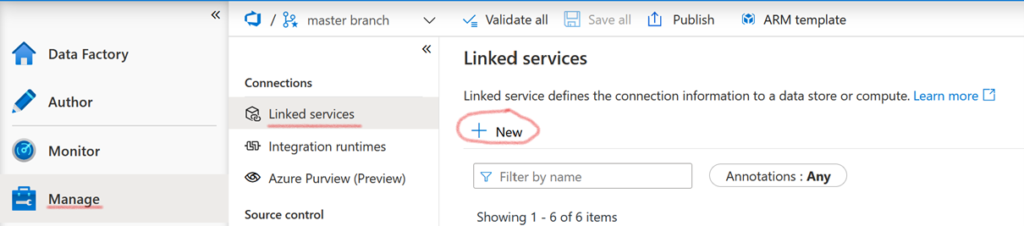
Avant cela, on va créer le linked service qui nous permettra d’accéder au keyvault. Dans le menu de votre ADF, suivez « Manage », puis « Linked Service » et enfin « + New ».
Sélectionnez ensuite « Azure Key Vault ».

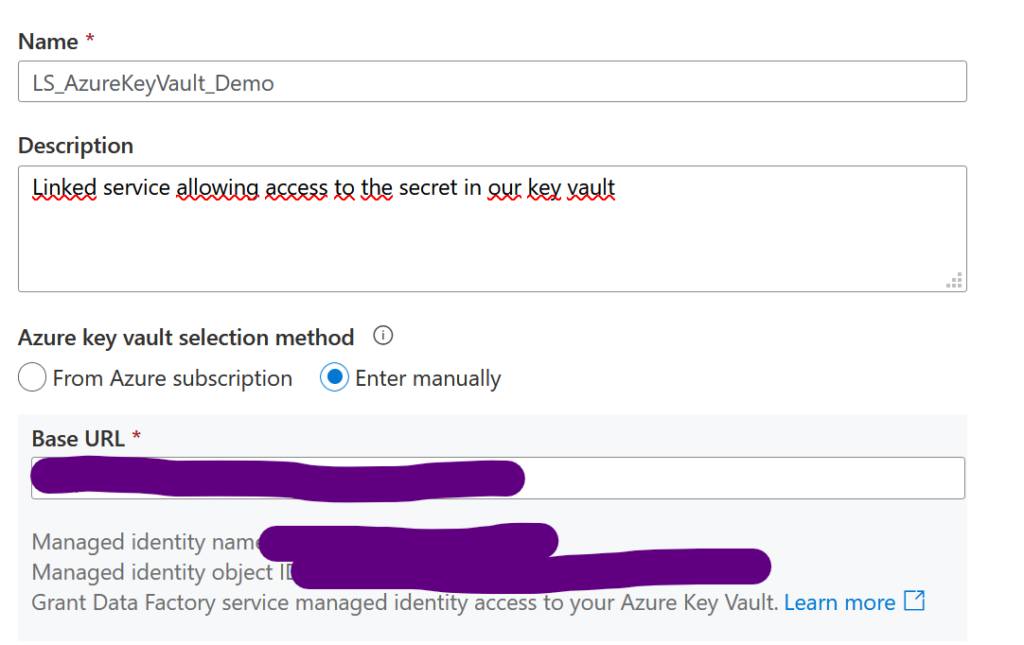
Choisissez le nom de votre linked service, puis entrez l’URL du keyvault cible (pour qu’il soit paramétré). Vous pouvez le trouver dans l’onglet « Overview » correspondant au keyvault sous « Vault URI ». Il n’y a rien d’autre à faire, puisqu’on a déjà autorisé notre ADF à accéder aux secrets du keyvault.
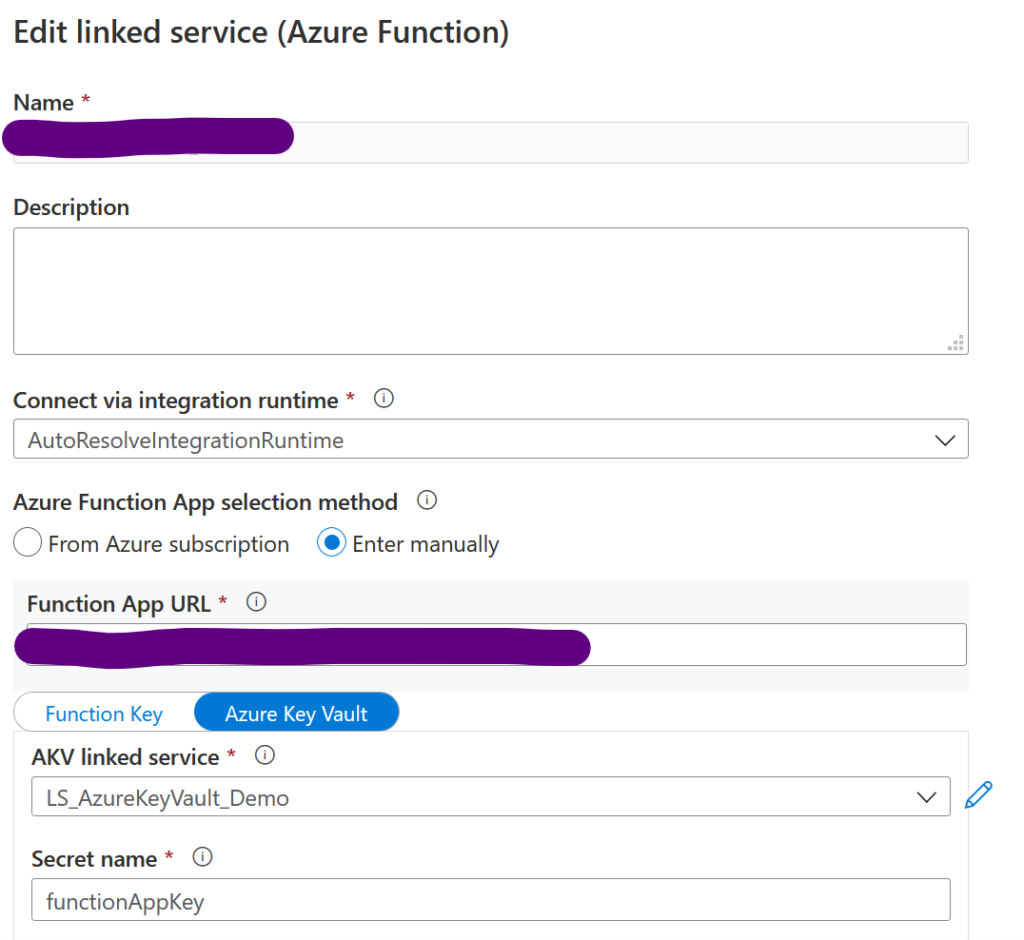
Ensuite lorsqu’on créé ses datasets, on peut passer par ce linked service. Voici deux exemples, pour une Azure Function et un Azure Blob Storage :
Dans ce cas-là, on utilise à la fois une URL, et un secret contenant la function app key. Les deux seront variabilisés.
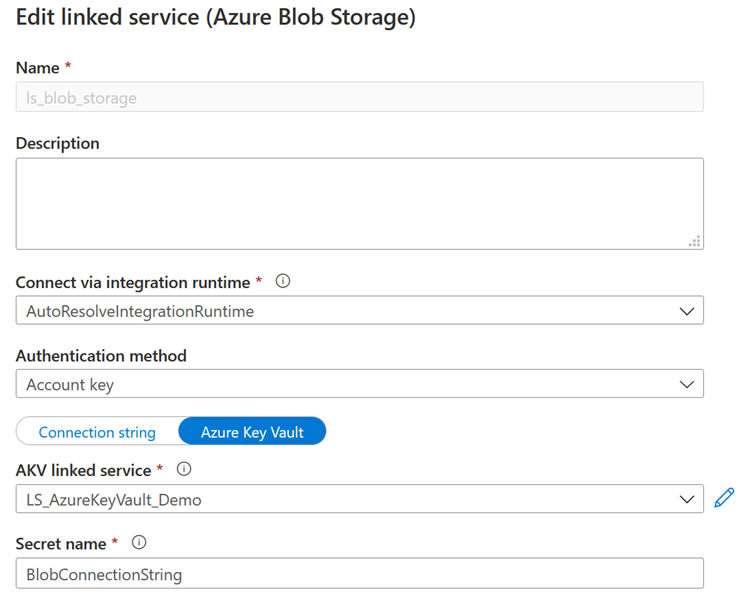
Dans ce cas-là, on utilise simplement la chaîne de connexion correspondant au Blob Storage, que l’on stocke dans le keyvault.
Encore une fois, il est possible de changer le template de génération des ARMs, si par exemple vous ne souhaitez pas passer par un keyvault. Mais cela peut être fastidieux et demandera des changements à chaque nouveau pipeline, data set ou data flow… Je conseille donc de ne le faire qu’en dernier recourt.
Maintenant que notre ADF source est lié à un répertoire GIT, que notre keyvault est alimenté des divers secrets nécessaires et que nos data sets sont correctement paramétrés, il ne nous reste plus qu’à exploiter les templates ARMs auto-générés dans un pipeline de déploiement :
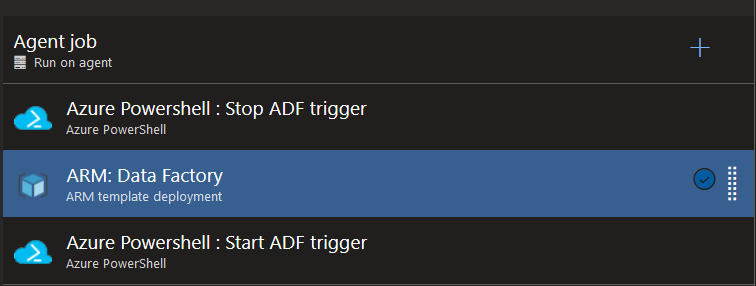
La première et la dernière tâche sont optionnelles, elles ne sont utiles que si votre ADF contient des triggers. Auquel cas, il faut les désactiver puis les réactiver après le déploiement. Dans les deux cas, on utilise une tâche Azure Powershell avec les scripts suivants (ADF_name correspond au nom de l’ADF et ResourceGroupName au nom de son ressource group) :
$triggersADF = Get-AzDataFactoryV2Trigger -DataFactoryName $(ADF_name) -ResourceGroupName $(ResourceGroupName)
$triggersADF | ForEach-Object { Stop-AzDataFactoryV2Trigger -ResourceGroupName $(ResourceGroupName) -DataFactoryName $(ADF_name) -Name $_.name -Force }
$triggersADF = Get-AzDataFactoryV2Trigger -DataFactoryName $(ADF_name) -ResourceGroupName $(ResourceGroupName)
$triggersADF | ForEach-Object { Start-AzDataFactoryV2Trigger -ResourceGroupName $(ResourceGroupName) -DataFactoryName $(ADF_name) -Name $_.name -Force }
La tâche restante exploite les ARMs auto-générés qui sont disponibles sur la branche adf_publish (par défaut), sous le dossier qui porte le nom de votre ADF de développement. Vous y trouvez deux fichiers : ARMTemplateForFactory.json et ARMTemplateParametersForFactory.json, respectivement le template ARM et ses paramètres.
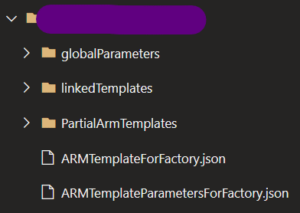
Il ne nous reste plus qu’à variabiliser les paramètres de ces fichiers, à savoir : le nom de l’ADF et les URLs. Si vous utilisez un keyvault par environnement, vous n’avez pas besoin de variabiliser les noms des secrets, sinon pensez à le faire (ils sont déjà considérés comme des paramètres de l’ARM). Le tour est joué ! Il ne reste plus qu’à dupliquer ce pipeline de déploiement pour chaque environnement.