
Les connecteurs Microsoft Graph jouent un rôle fondamental en ouvrant Graph à des données extérieures à l’écosystème Microsoft 365. L’utilisation d’un connecteur Graph en conjonction avec Microsoft Search améliore considérablement la complétude de l’indexation des données de l’entreprise. Cela permet d’élargir les capacités de recherche au-delà du contenu Microsoft 365.
Je vous partage ici quelques notes issues de mon expérience afin de démystifier certains concepts et de mettre en lumière certains points d’attention importants lors de mise en œuvre de connecteurs Graph.
Commençons par poser quelques éléments de contexte.
Microsoft a annoncé la possibilité d’étendre Graph avec des connecteurs personnalisés dès novembre 2019, lors de la conférence Microsoft Ignite. Cette annonce faisait partie d’une série d’extensions et d’améliorations de Microsoft Graph visant à augmenter sa flexibilité et sa capacité à intégrer diverses sources de données et services, offrant ainsi une expérience plus unifiée et intégrée aux utilisateurs et aux développeurs.
Le SDK a pour sa part été annoncé en early preview à la conférence Build de 2022 (https://devblogs.microsoft.com/microsoft365dev/increase-engagement-and-discoverability-of-your-data-with-microsoft-graph-connectors/).
Il a ensuite été annoncé de manière officielle à Build 2023 (https://www.microsoft.com/en-us/microsoft-365/blog/2023/05/23/empowering-every-developer-with-plugins-for-microsoft-365-copilot/)
En résumé, le principe n’est pas neuf mais sa concrétisation l’est beaucoup plus!
Nous l’avons vu en introduction, les connecteurs permettent d’injecter des données de systèmes externes dans Graph, permettant ainsi de les indexer et de donner une vision plus complète des données de l’entreprise. Certes, mais pour quoi faire?
Injecter des données de systèmes externes dans Microsoft Graph via des connecteurs offre des avantages considérables en termes d’accessibilité et d’intelligence des données. Cette intégration centralisée ouvre la porte à des recherches sémantiques avancées qui comprennent le contexte et le sens des termes recherchés, bien au-delà de simples mots-clés. Ainsi, au lieu de rechercher des données isolément dans chaque système, Graph permet aux utilisateurs de réaliser des requêtes transversales qui exploitent, analysent et interprètent l’ensemble des données de l’entreprise, englobant à la fois les données internes et externes.
Par conséquent, plutôt que de jongler entre les interfaces de multiples systèmes externes, souvent disparates et sans liens entre elles, les utilisateurs bénéficient d’une expérience unifiée et cohérente à travers Graph.
Un connecteur Graph peut être considéré comme une déclinaison du pattern Retrieval-Augmented Generation (RAG), centrée sur contexte de Copilot. Ce pattern combine la récupération d’informations pertinentes d’une part et la génération de contenu d’autre part. Il s’appuie sur une base de données vectorielle pour enrichir et contextualiser les réponses générées par un modèle génératif.
Dans cette optique, le connecteur Graph fonctionne comme la composante de récupération du pattern RAG : il extrait et rend accessibles les données des systèmes externes à Copilot, permettant ainsi de générer des réponses précises et contextualisées.
La sophistication des connecteurs Graph réside dans leur outillage (c’est-à-dire l’API et les interfaces administratives). Couplé avec Copilot, un connecteur offre donc un usage avancé et industrialisé du pattern RAG au sein de l’écosystème Microsoft.
Avant de foncer tête baissée dans l’implémentation d’un nouveau connecteur, il convient de se demander si c’est bien d’un connecteur dont on a besoin.
Nous l’avons vu, un connecteur permet d’importer des données externes à Microsoft 365 et de les indexer vectoriellement pour effectuer des recherches sémantiques. Les données de référence, qui sont relativement statiques et ne changent pas fréquemment, sont en effet des candidates idéales pour l’ingestion via un connecteur Graph. Ces données peuvent inclure des informations d’entreprise telles que les nomenclatures de produits, les informations sur l’organisation, les annuaires d’entreprise, ou les bases de données de connaissances. L’avantage d’indexer de telles données réside dans leur pertinence à long terme et leur nécessité dans les recherches récurrentes, ce qui justifie leur intégration dans un index vectoriel pour des recherches sémantiques efficaces et rapides au sein de l’écosystème Microsoft 365.
En revanche, si l’exigence est d’avoir un accès en temps réel aux données, sans la nécessité de les indexer, un plugin serait plus approprié. Les plugins interagissent directement avec les systèmes externes, ce qui est idéal pour les scénarios nécessitant des données les plus fraiches possibles ou pour intégrer des fonctionnalités en temps réel.
Il faut également prendre en compte la limitation de Microsoft Graph, qui est de 10 connexions par organisation (bien que cette limite puisse être augmentée sur demande). Cette limite est importante à considérer dans le cadre de la planification de l’architecture d’intégration de données de l’entreprise.

La mise en œuvre d’un connecteur dans une entreprise soulève la question des responsabilités et de définir les rôles de chaque équipe impliquée. Au cœur de ce processus se trouve la pratique de l’intégration, qui joue un rôle central car l’essence de la création d’un connecteur Graph se résume fondamentalement à un problématique ETL (Extraction, Transformation, Chargement).
Partant de là, il convient de considérer 2 aspects topologiques essentiels :
La structure exacte du partage des responsabilités variera donc d’une entreprise à l’autre, et variera certainement également dans le temps. Le point central ici n’est pas de discuter de ces éléments topologiques (c’est un sujet à part entière, qui dépasse largement le cadre de cet article) mais de souligner qu’il s’agit bel et bien d’un projet d’intégration. En conséquence, l’organisation associée sera similaire à celle de n’importe quel autre projet d’intégration.
Un connecteur est fondamentalement assez simple. Il est composé des 3 à 4 éléments suivants :
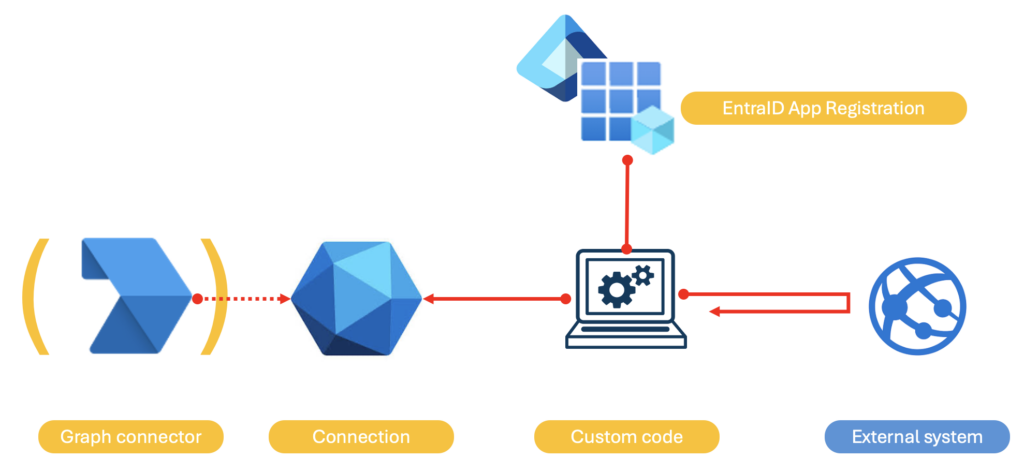
Dans la littérature actuellement disponible, les termes connecteur et connexion sont souvent utilisés de manière interchangeable alors que je les ai séparés au paragraphe précédent.
En effet, ce mélange est en réalité un très léger abus de langage :
NOTE : le schéma évoqué plus haut est constitué de :
La structure de l’application qui va effectivement implémenter la logique d’interaction avec Graph (c’est-à-dire le custom code évoqué plus haut) peut varier largement, s’adaptant à la complexité des données et aux exigences de l’entreprise. Fondamentalement, elle encapsule la logique d’interaction avec l’API Graph pour :
Au plus simple, un script PowerShell peut suffire pour des tâches d’intégration de base, exploitant l’accessibilité et la simplicité de la ligne de commande pour effectuer des synchronisations périodiques de données. À l’opposé, pour des solutions à fort volume de données et/ou plus réactives, une application serverless orientée événements utilisant par exemple des Azure Functions peut être plus adaptée.
Pour déterminer l’architecture la plus adaptée, il convient de se poser les questions suivantes :
Etc. Les réponses à ces questions guideront le choix entre une solution simple ou évoluée.
Au passage, toutes ces questions rappellent évidemment très fortement les questions que l’on se pose classiquement dans un projet d’Intégration. Et pour cause : comme expliqué plus haut, il s’agit d’un projet d’intégration comme un autre!
Enfin, il convient de prendre en compte certaines limitations de l’API, qu’il faut donc savoir gérer proprement:
Des mécanismes de throttling adaptés peuvent donc s’imposer en fonction du volume des données à injecter et de la fréquence de mise à jour de ces données.
En complément, pour un connecteur vraiment résilient, une stratégie de retry éventuellement associée à un découplage entre les fonctions d’extraction et de chargement peuvent s’avérer nécessaires.
Le contrôle de l’accès aux données injectées via un connecteur Graph pose évidemment de grosses questions. Le défi semble a priori encore plus important lorsque le système externe, source de ces données, ne s’appuie pas sur EntraID pour gérer l’accès à ses données : comment faire correspondre les modèles de sécurité de Graph et dudit système? Comment s’assurer qu’un utilisateur n’ait pas accès dans Graph à une donnée qui devrait lui être interdite?
Heureusement, il est possible de « synchroniser » les permissions. Cela passe par 2 mécanismes complémentaires :
Un dernier point qui mérite d’être souligné : à l’heure de l’écriture de ces lignes, Copilot supporte uniquement des prompts simples qui contiennent explicitement le titre de l’item injecté au travers du connecteur.
Par exemple, imaginons que l’on injecte les informations de sociétés partenaires, et que le titre complet de chacun des item (c’est-à-dire chacune desdites sociétés) soit le nom de l’entreprise. Les prompts à Copilot devront alors porter explicitement sur le nom de l’entreprise et rester simple :
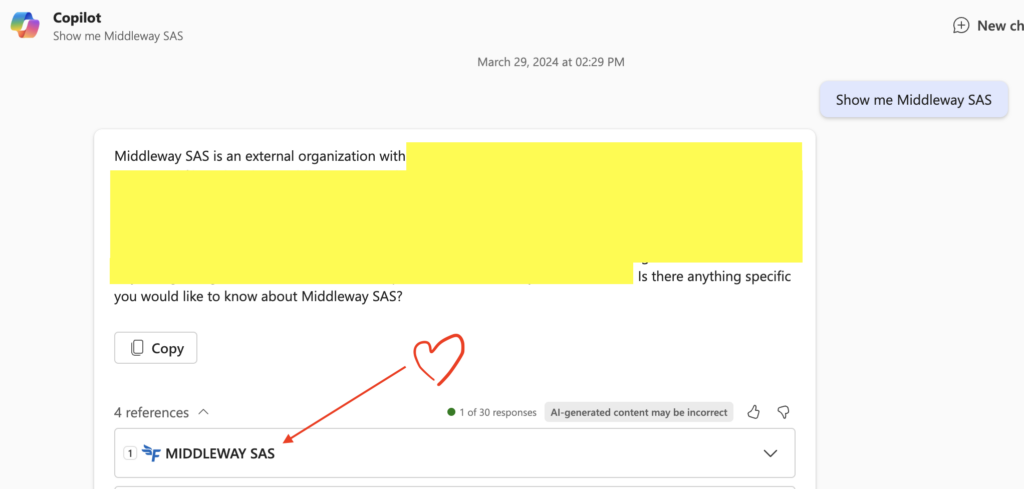
Dans le cas contraire, les résultats seront aléatoires. Je demande dans l’exemple ci-dessous des informations un peu plus avancées, contenues non pas dans le titre mais dans le corps de l’item. Dans ce cas parfois Copilot trouvera les informations demandées, comme ci-dessous :
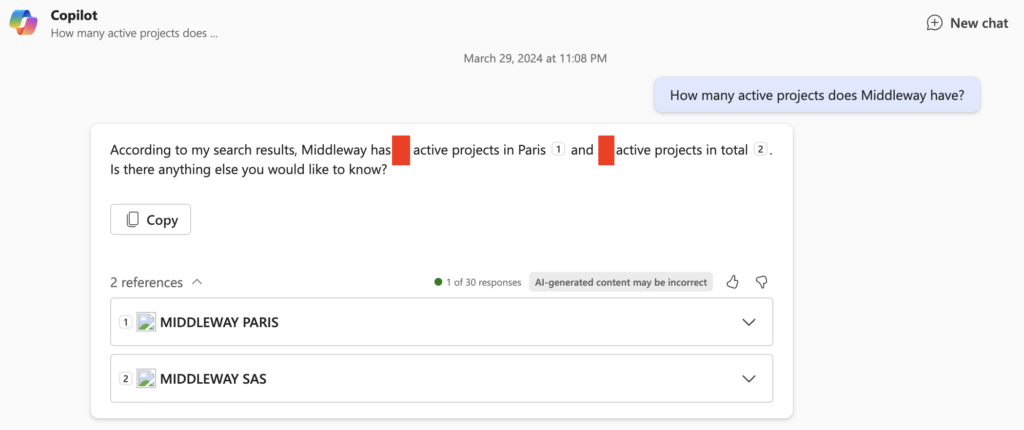
Et parfois non :
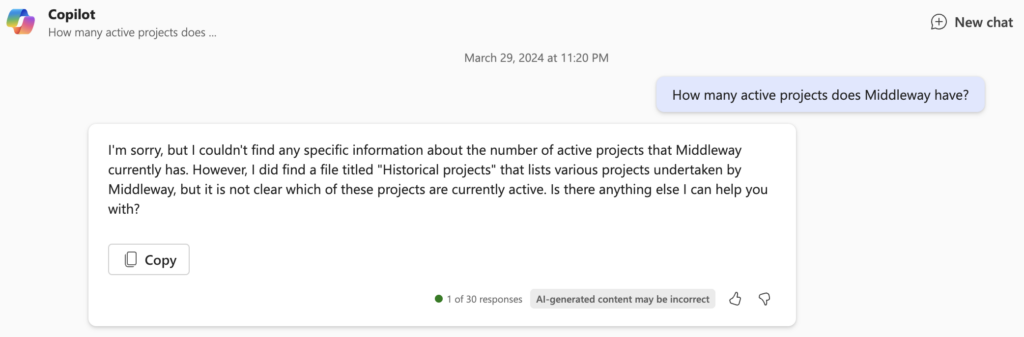
Vous allez dire « tout ça pour ça », et c’est vrai que ça peut être décevant de prime abord. Mais cette limitation est connue et Microsoft travaille très activement à améliorer l’exploitabilité des données issues des connecteurs. Il est d’ailleurs possible qu’au moment de la publication de cet article, cette limitation soit déjà levée.
La création d’un connecteur Graph est techniquement un jeu d’enfant : les APIs et SDKs mis à disposition par Microsoft permettent d’abaisser la complexité de mise en oeuvre.
En revanche, il est important de garder en tête qu’il s’agit d’un projet d’intégration à part entière. Il convient donc de le mener avec toute la rigueur qui s’impose pour ce genre de projet.