
Microsoft Graph connectors play a fundamental role by opening Graph to data external to the Microsoft 365 ecosystem. Using a Graph connector in conjunction with Microsoft Search significantly enhances the completeness of the company’s data indexing. This allows for expanding search capabilities beyond Microsoft 365 content.
Here, I share some notes from my experience to demystify certain concepts and highlight some important points of attention during the implementation of Graph connectors.
Let’s start by setting some context.
Microsoft announced the ability to extend Graph with custom connectors in November 2019, during the Microsoft Ignite conference. This announcement was part of a series of extensions and enhancements to Microsoft Graph aimed at increasing its flexibility and its capacity to integrate various data sources and services, thus offering a more unified and integrated experience to users and developers.
The SDK, for its part, was announced in early preview at the Build conference of 2022 (https://devblogs.microsoft.com/microsoft365dev/increase-engagement-and-discoverability-of-your-data-with-microsoft-graph-connectors/).
It was then officially announced at Build 2023 (https://www.microsoft.com/en-us/microsoft-365/blog/2023/05/23/empowering-every-developer-with-plugins-for-microsoft-365-copilot/).
In summary, the principle is not new, but its realization is much more so!
As we saw in the introduction, connectors allow the injection of data from external systems into Graph, thereby enabling their indexing and providing a more complete view of the company’s data. Sure, but to what end?
Injecting data from external systems into Microsoft Graph via connectors offers considerable advantages in terms of data accessibility and intelligence. This centralized integration opens the door to advanced semantic searches that understand the context and meaning of searched terms, well beyond mere keywords. Thus, instead of searching for data in isolation within each system, Graph allows users to perform cross-system queries that exploit, analyze, and interpret the entirety of the company’s data, encompassing both internal and external data.
Therefore, rather than juggling the interfaces of multiple, often disparate and unlinked external systems, users benefit from a unified and consistent experience across Graph.
A Graph connector can be considered a variation of the Retrieval-Augmented Generation (RAG) pattern, focused on the context of Copilot. This pattern combines the retrieval of relevant information on one hand and the generation of content on the other. It relies on a vector database to enrich and contextualize the responses generated by a generative model.
In this light, the Graph connector functions as the retrieval component of the RAG pattern: it extracts and makes data from external systems accessible to Copilot, thus allowing for the generation of accurate and contextualized responses.
The sophistication of Graph connectors lies in their tooling (that is, the API and administrative interfaces). Coupled with Copilot, a connector thus offers an advanced and industrialized use of the RAG pattern within the Microsoft ecosystem.
Before diving headfirst into implementing a new connector, it’s important to ask whether a connector is truly what’s needed.
As we’ve seen, a connector allows for the importation of external data into Microsoft 365 and its vectorial indexing for semantic search purposes. Reference data, which is relatively static and does not change frequently, indeed makes for ideal candidates for ingestion via a Graph connector. Such data can include company information like product nomenclatures, organizational details, company directories, or knowledge bases. The advantage of indexing such data lies in its long-term relevance and the necessity for recurrent searches, justifying their integration into a vector index for efficient and rapid semantic searches within the Microsoft 365 ecosystem.
On the other hand, if the requirement is to have real-time access to data, without the need for indexing, a plugin would be more appropriate. Plugins interact directly with external systems, which is ideal for scenarios requiring the freshest data possible or for integrating real-time functionalities.
The limitation of Microsoft Graph, which is 10 connections per organization (although this limit can be increased upon request), must also be taken into account. This limit is important to consider when planning the data integration architecture of the company.

Who should take on the responsibility for the connectors?
Implementing a connector within a company raises questions of responsibility and definition of the roles of each involved team. At the heart of this process lies the practice of integration, which plays a central role since the essence of creating a Graph connector essentially boils down to an ETL (Extraction, Transformation, Load) issue.
From this perspective, it is appropriate to consider two essential topological aspects:
Thus, the exact structure of responsibility sharing will vary from one company to another and will certainly also change over time. The central point here is not to discuss these topological elements (that’s a topic in its own right, far beyond the scope of this article) but to emphasize that this is indeed an Integration project. Consequently, the associated organization will be similar to that of any other integration project.
A connector is fundamentally quite simple. It consists of the following 3 to 4 elements:
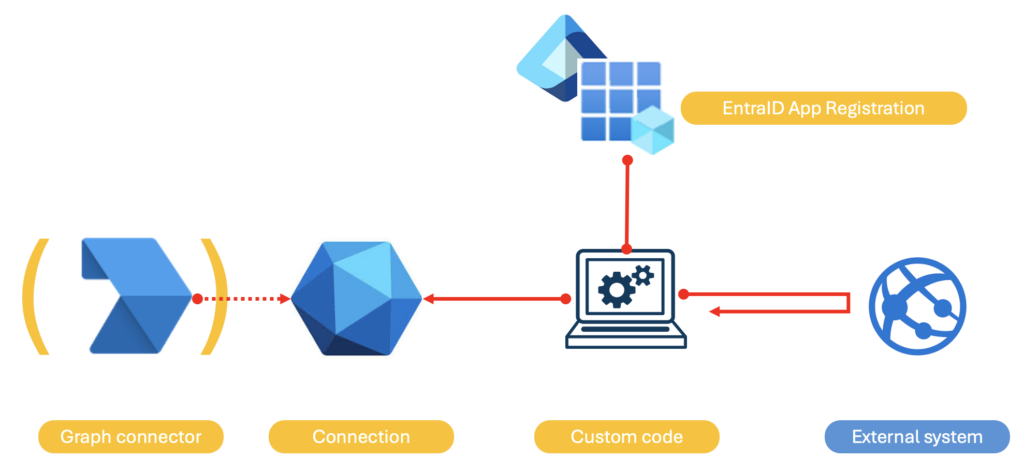
In the literature currently available, the terms connector and connection are often used interchangeably, even though I separated them in the previous paragraph.
Indeed, this mix-up is actually a very slight misuse of terms:
NOTE: the schema mentioned above consists of:
The structure of the application that will actually implement the logic of interaction with Graph (i.e., the custom code mentioned above) can vary widely, adapting to the complexity of the data and the requirements of the company. Fundamentally, it encapsulates the logic of interaction with the Graph API to:
At its simplest, a PowerShell script may suffice for basic integration tasks, exploiting the accessibility and simplicity of the command line to perform periodic data synchronizations. On the other hand, for solutions with a high volume of data and/or more reactive needs, a serverless, event-driven application using, for example, Azure Functions might be more appropriate.
To determine the most appropriate architecture, the following questions should be considered:
Etc. The answers to these questions will guide the choice between a simple or advanced solution.
By the way, all these questions strongly recall those typically asked in an Integration project. And for good reason: as explained earlier, it is an integration project like any other!
Finally, it is important to consider certain limitations of the API that must be properly managed:
Appropriate throttling mechanisms may therefore be required depending on the volume of data to inject and the frequency of updating this data.
In addition, for a truly resilient connector, a retry strategy possibly associated with a decoupling between extraction and loading functions may prove necessary.
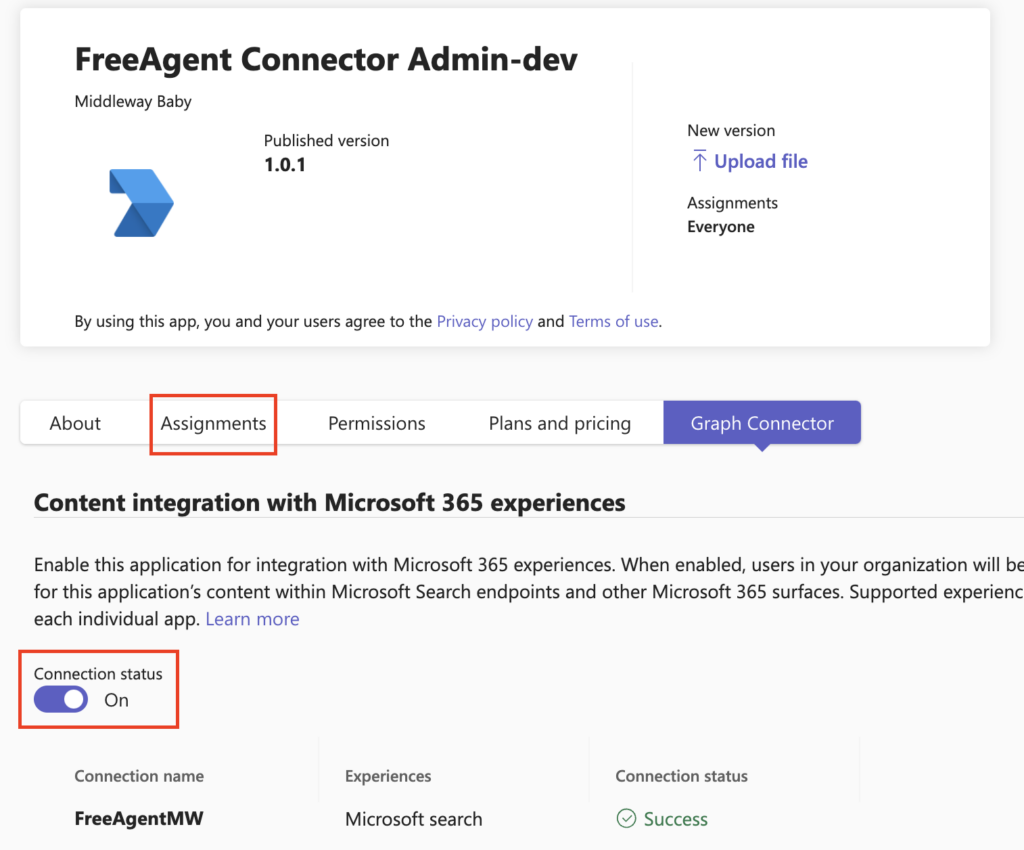
Controlling access to data injected via a Graph connector obviously raises significant questions. The challenge seems even greater when the external system, the source of this data, does not rely on EntraID to manage access to its data: how to match the security models of Graph and said system? How to ensure that a user does not have access in Graph to data that should be prohibited to them?
Fortunately, it is possible to “synchronize” permissions. This is done through two complementary mechanisms:
One last point that deserves emphasis: at the time of writing these lines, Copilot only supports simple prompts that explicitly contain the title of the item injected through the connector.
For example, imagine injecting information about partner companies, and that the complete title of each item (i.e., each of said companies) is the name of the company. The prompts to Copilot will then have to explicitly focus on the company name and remain simple:
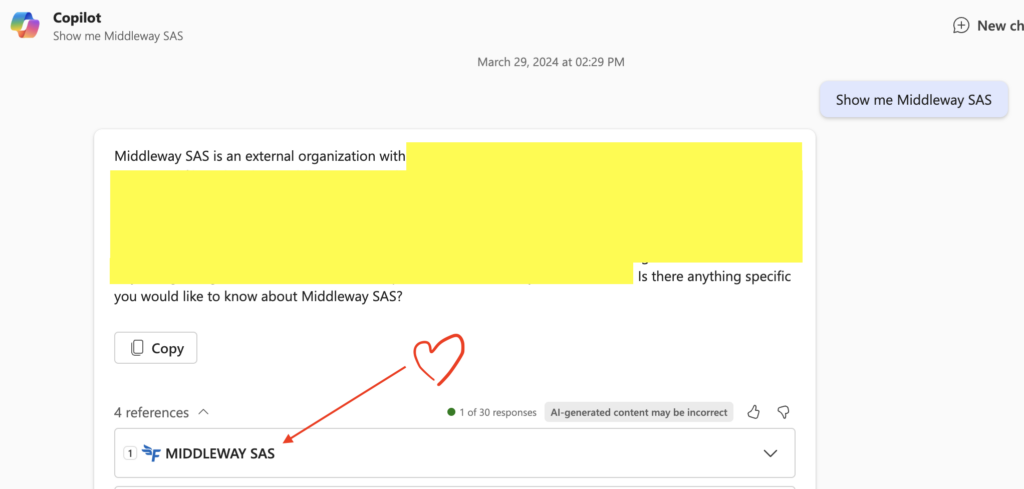
Otherwise, the results will be random. For example in the below screenshot, I ask for more advanced information, contained not in the title but in the body of the item. The consequence is that sometimes Copilot will find the requested information, as below:
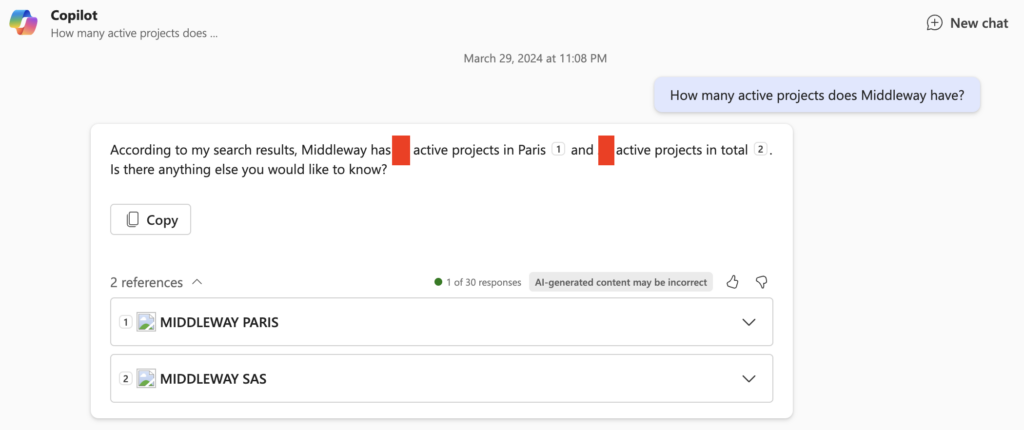
And sometimes not:
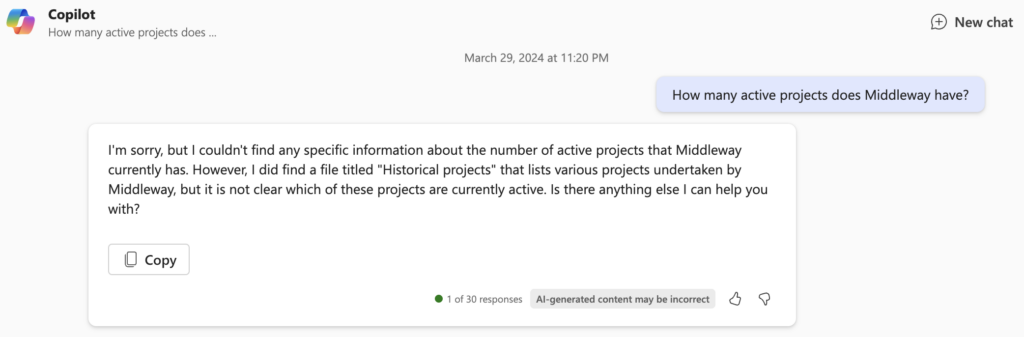
You might say, “all this for that,” and it’s true that it can be disappointing at first glance. But this limitation is known, and Microsoft is working very actively to improve the exploitability of data from connectors. It is also possible that by the time this article is published, this limitation has already been lifted.
Creating a Graph connector is technically a piece of cake: the APIs and SDKs provided by Microsoft help to lower the implementation complexity. However, it’s important to keep in mind that this is a full-fledged integration project. Therefore, it should be conducted with all the rigor that this type of project demands.