
Fabric est la nouvelle data platform end-to-end de Microsoft. Elle combine plusieurs outils propres à ce domaine comme Azure Synapse Analytics, Data Factory et Power BI. Cela permet d’intégrer, transformer, analyser et visualiser les données au même endroit, facilitant la collaboration parmi les spécialistes des données.
Power BI est l’ensemble de services et outils Microsoft dédiés à la visualisation de données. Auparavant, il existait une version PowerBI Desktop, exécutée en local, principalement utilisée pour le développement. Ensuite, on utilisait le Power BI Service, en ligne, pour publier et partager les tableaux de bord ainsi que gérer la sécurité.
Les utilisateur habituels des composants Azure Synapse Analytics, Data Factory et Power BI retrouveront les interfaces habituelles dans Fabric. Par exemple, l’interface du composant DataFlow Gen 2 est la même que celle de Power Query dans Power BI. Les data pipelines reprennent également les pipelines de Data Factory. Et les notebooks utilisées dans Synapse Data Engineering sont identiques aux notebooks de Synapse Analytics.
Les principaux langages utilisés sont toujours le SQL pour l’entrepôt de données, le Python pour l’intégration et l’analyse des données via les notebooks, le language M pour la transformation des donnés dans Dataflow Gen 2 et le DAX pour créer des mesures dans Power BI.
Ceci dit, Fabric offre aussi une expérience low-code qui simplifie le travail:
Comme vu précédemment, le fait d’avoir tous les composants au même endroit permet d’être plus efficace en termes d’organisation, de consommation de ressources et de collaboration. Toute l’architecture BI est au même endroit, divisée par couches selon une architecture en médaillon (couches bronze, silver et gold).
Un meilleur data management est ainsi garanti.
Un des principaux points forts de Fabric est OneLake. Ce data Lake, défini comme le « OneDrive pour les données », rend les données stockées à cet endroit directement visibles par tous les composants. Cela comporte l’optimisation des ressources et l’interopérabilité des données, tout en évitant la duplication ou le mouvement de données.
Dans Fabric, il est possible d’améliorer l’intégration et le déploiement continu des modèles sémantiques de données et des rapports grâce à Azure Git et les pipelines de déploiement de Fabric. C’est fini les doublons de rapports partout et le partage sous-optimale dans SharePoint !
Le DataFlow Gen2, assemblable à Power Query dans Power BI, est le composant « ETL » low-code de Fabric, qui permet d’extraire, transformer et ensuite charger les données exploitables pour la visualisation. L’avantage est que cela se trouve déjà dans le cloud, pas besoin de télécharger un modèle sémantique de données en local pour transformer les données et le republier comme dans le cas de Power Query.
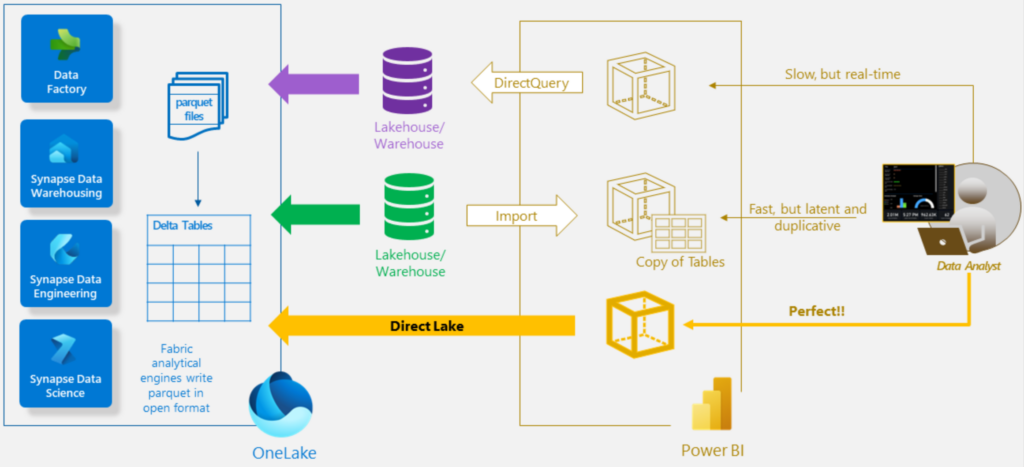
Dans Power BI, les modes les plus fréquents de connexions aux données sources sont le mode Import et le mode Direct Query.
En mode Import, les données sont mises en cache pour de meilleures performances concernant surtout les grands modèles de données. Cependant, les modifications de la source ne sont récupérées qu’à l’actualisation.
Au contraire, en Direct Query, les données sont interrogées à la source, ce qui peut être plus lent, mais reflète immédiatement les modifications de la source. Dans ce mode, les transformations de données possibles dans Power Query sont par contre limitées.
Dans Fabric (mais aussi avec une licence Microsoft Premium hors Fabric), les données sont chargées directement à partir de OneLake. Cela offre des performances similaires à l’importation tout en reflétant les modifications de la source en temps réel. Idéal pour les grands modèles et les modèles avec des mises à jour fréquentes (source : Microsoft).
Microsoft Fabric propose plusieurs options d’achat de capacités.
Les capacités sont calculées en Stock Keeping Units (SKU). Chaque SKU a une différente puissance de calcul, mesurée par sa valeur de capacité (CU).
Il existe deux types de SKU :
Pour utiliser Fabric, il faut avoir une licence F ou P et au moins une licence par utilisateur.
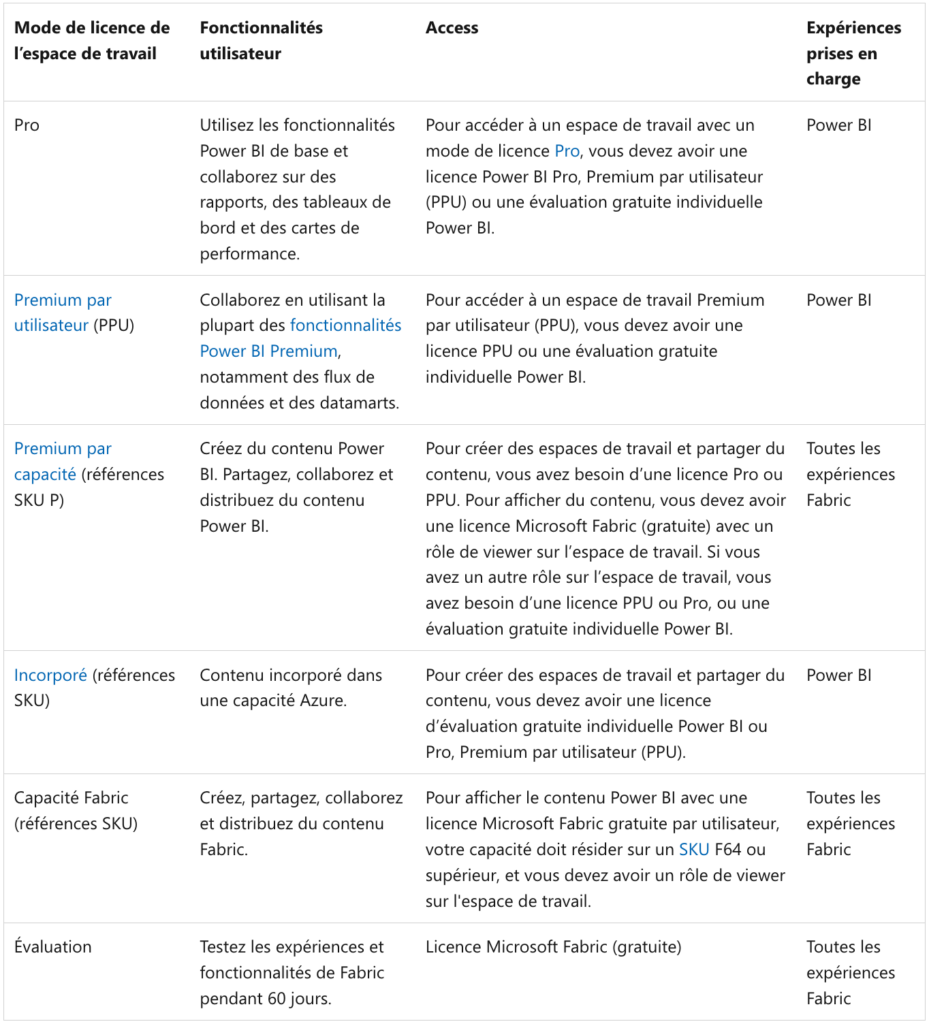
Les capacités sont affectées aux espaces de travail dans Fabric selon le mode de licence des espaces de travail. Voici un tableau fourni par Microsoft qui résume ce concept :
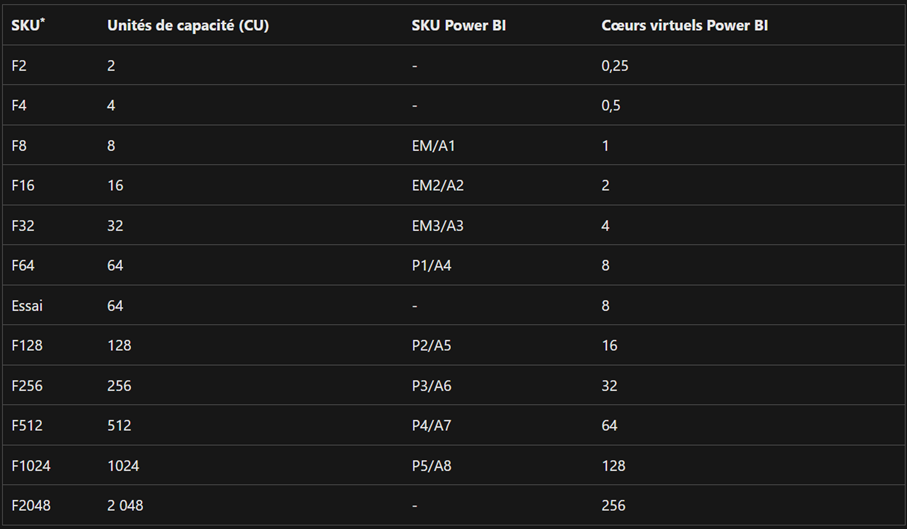
Une capacité est l’ensemble de ressources pour une utilisation déterminée. Chaque capacité propose un certain nombre de SKU selon la puissance de calcul nécessaire. Nous calculons cette puissance en Capacity Units (CU). Voici un deuxième tableau de Microsoft qui schématise le rapport entre les SKU Fabric, les CU, les SKU Power BI et les virtual cores Power BI.
Il faut bien noter que les SKU Power BI Premium P prennent en charge Microsoft Fabric. Les références SKU A et EM prennent uniquement en charge des éléments Power BI.
*Les références SKU inférieures à F64 nécessitent une licence Pro ou Premium par utilisateur (PPU), ou une évaluation gratuite individuelle Power BI pour consommer du contenu Power BI.
Et voici les coûts des ces licences en juillet 2024, par consommation ou par réservation :
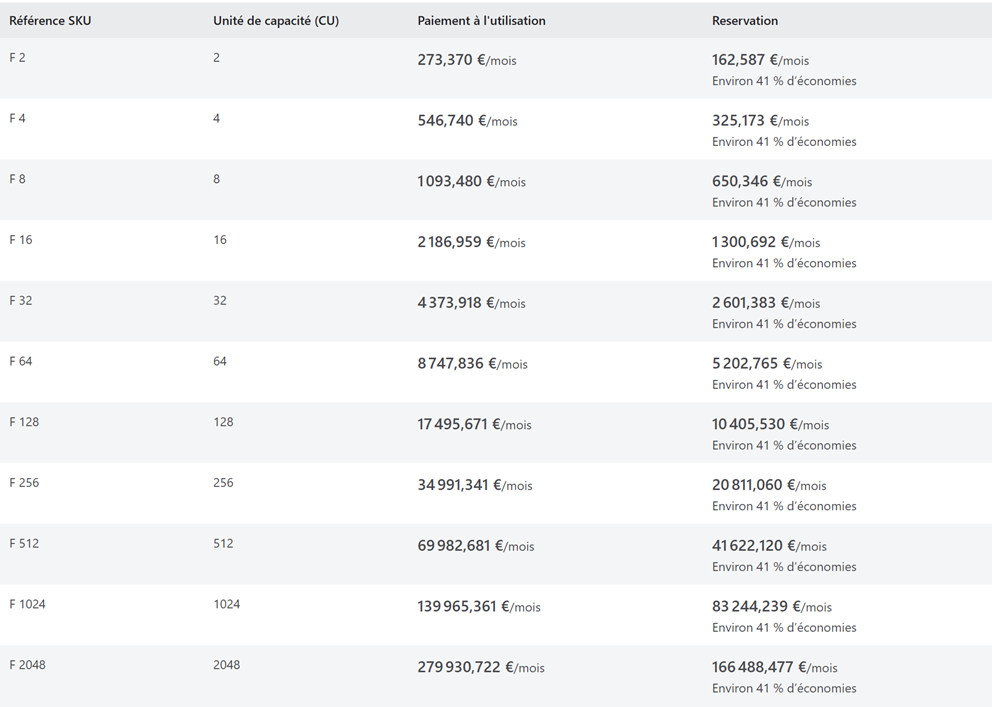
Plus d’information sur les coûts ici : Fabric Pricing
Par contre, cette licence permet d’accéder qu’aux éléments Power BI dans Fabric.
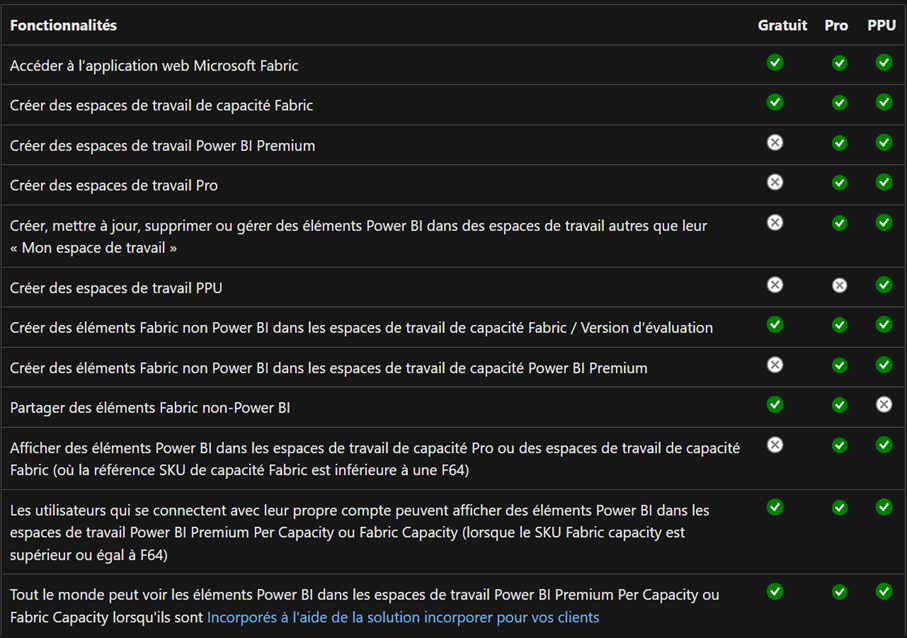
Voici les fonctionnalités pour chaque licence dans ce tableau Microsoft :
En conclusion, l’utilisation de Power BI dans Microsoft Fabric permet de consommer des données centralisées dans le OneLake. Cela offre également un meilleur data management et améliore la collaboration parmi les différents data specialists tout en optimisant les ressources et les coûts associés.