
Lors de la conception d’un flux de migration de données avec SSIS nous devons constamment avoir à l’esprit le fonctionnement de SSIS. Mon objectif est de partager mon expérience lorsqu’on doit traiter un grand volume de données. Au travers d’un exemple, je souhaite montrer quelques optimisations pertinentes. Mon exemple concerne le transfert de données entre 2 bases données Microsoft SQL Server. La plupart du temps, lorsque j’ai eu à concevoir un package SSIS, les principales considérations étaient de plan technique :
Au travers de cet article, nous nous focaliserons essentiellement sur des concepts simples qui permettent d’améliorer les temps de traitement car, j’ai personnellement rencontré des scénarios ETL impliquant un grand volume de données et résultant sur un temps de traitement très long. Imaginez simplement un package SSIS devant traiter 50 millions de lignes SQL : en fonction de la conception du flux, vous pouvez observer des temps allant de plusieurs jours à quelques heures.
Pour notre premier cas, supposons que notre besoin soit simplement d’insérer des données d’une base de données source à une base de données cible. Ce scénario est un cas très simple car SSIS fournit des composants optimisés et utilisables directement. Pour réaliser votre flux, ajouter un composant « data flow task » sur votre onglet « Control flow ». Dans l’onglet « Data flow », ajouter un composant de type « OLE DB Source » puis sélectionnez ou configuez votre connexion vers votre serveur de base de données. Choisissez « table or view » comme mode d’accès. A partir d’ici, si vous n’avez pas besoin de toutes les colonnes de votre source de données, précisez uniquement les colonnes que vous souhaitez. Pour ce faire, utilisez l’onglet « Column » de l’assistant de configuration.
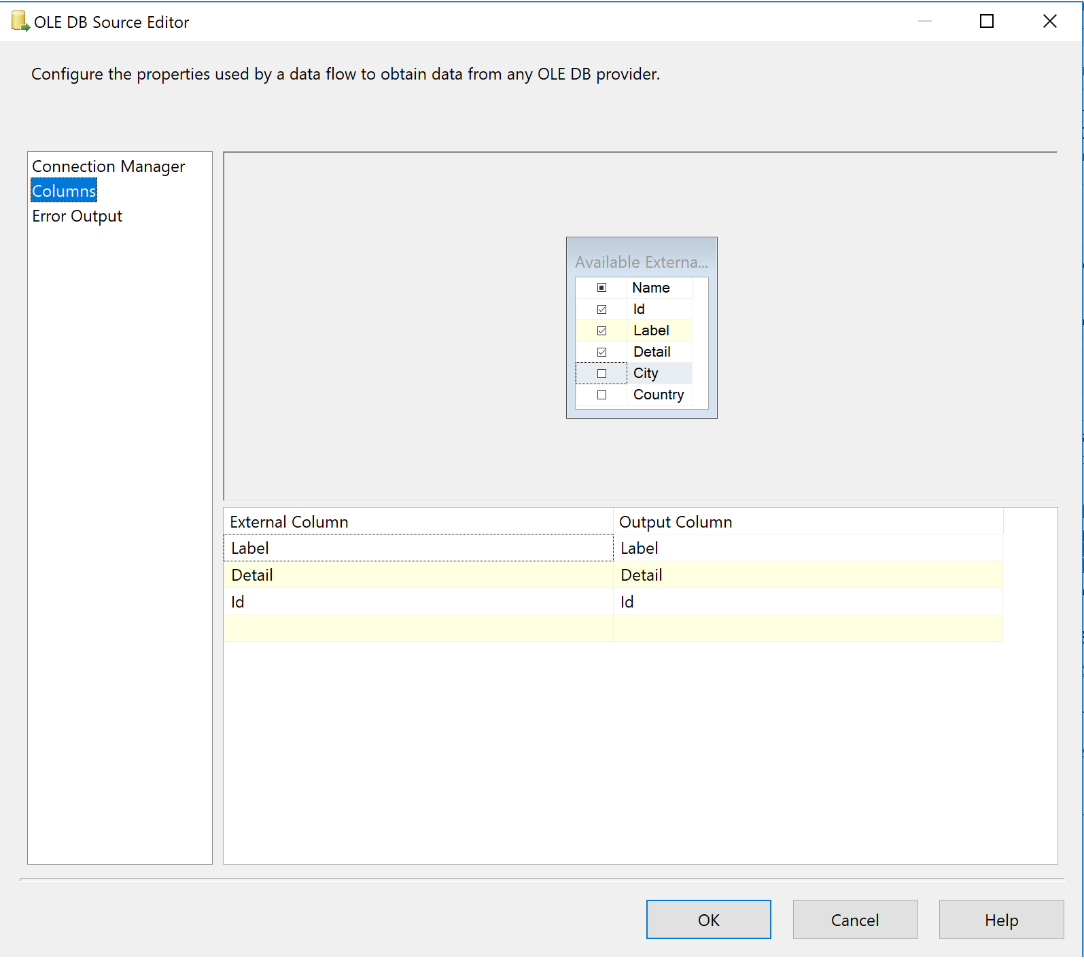
Maintenant le composant source est configuré. Nous allons simplement ajouter un composant de destination de type « OLE DB Destination component » pour préciser notre base et notre table de destination. A cette étape, il faut faire attention aux paramètres suivants :
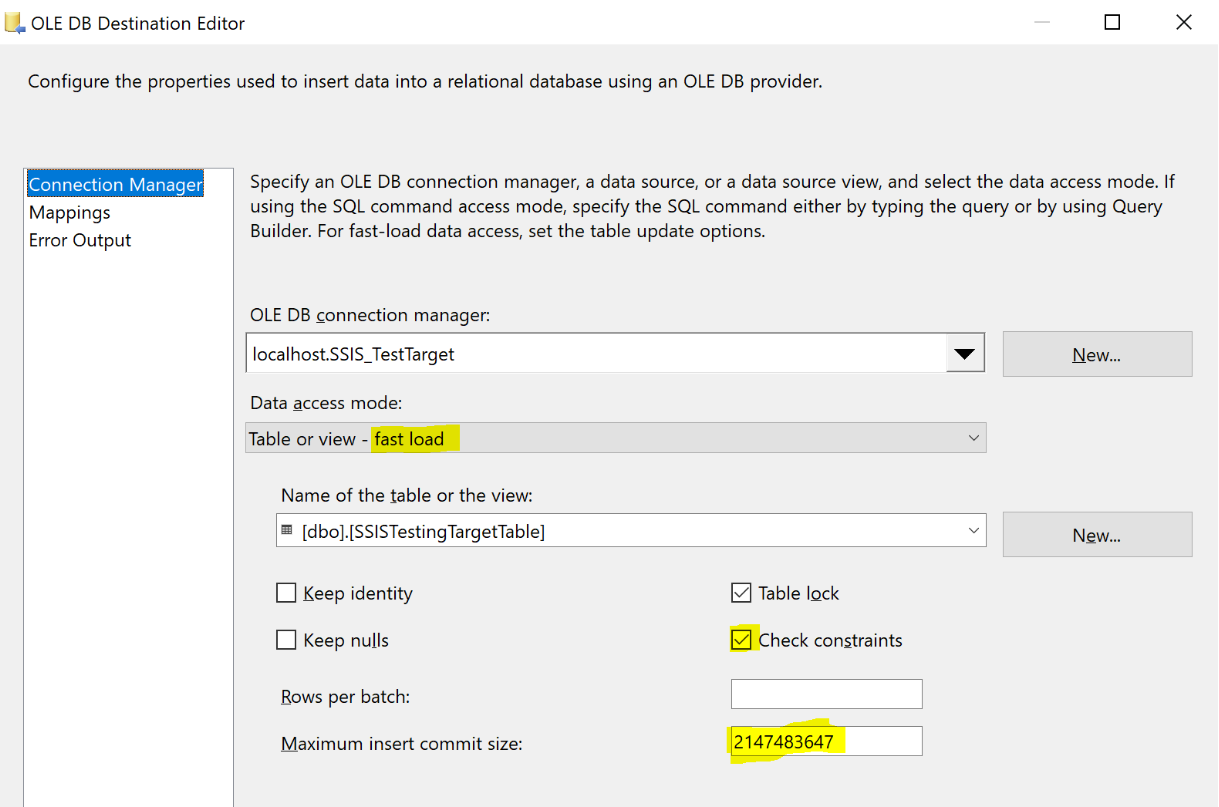
D’autres facettes peuvent être explorées pour optimiser les traitements mais ces points sont à minima ceux que vous devez absolument traiter.
Biensûr, n’oubliez pas de faire votre mapping pour définir les colonnes cibles pour les insertions.
Même s’il est vrai que SSIS est particulièrement performant lors de l’insertion de données, il n’est clairement pas conçu pour de la mise à jour en masse. Donc, si vous avez beaucoup de données à mettre à jour, n’utilisez surtout pas une requête de type « Update » dans un composant OLE DB Destination. Vous arriverez probablement à votre fin mais le temps de traitement des données sera trop important pour une mise en production. Ce comportement ce produit car vous ne pourrez pas réaliser votre traitement sous une seule transaction et vous serrez contraint de réaliser une transaction par mise à jour. De plus, c’est aujourd’hui considéré comme une erreur majeure de conception. A la place, il faut préférer, et cela est admis par la communauté, d’utiliser des tables de travail ou des tables temporaires. Concrètement :
Une fois que vos données sont dans la table de travail, l’utilisation d’une procédure stockée vous permettra d’avoir une mise à jour de type « Bulk » et de réaliser votre traitement sous une seule transaction. C’est impossible si les données sont réparti sur 2 serveurs différents.
Vous vous demandez certainement s’il sera plus difficile de savoir qu’est ce qui à été mis à jour ou inséré avec succès . Oui ce sera plus difficile. C’est une approche de type « tout ou rien ». Vous pouvez, par exemple réaliser des insertions par batch dont vous maîtrisez/limitez la taille (au lieu de tout mettre à jour, ne traiter qu’un lot de 1 million de lignes par exemple) : cela permettra une traçabilité sur chaque lot, mais bien entendu, c’est grandement dépendant de vos besoins.