
This post is about SSIS consideration while designing a data migration control flow between databases. The main goal is to optimize our whole process. Above the business process we handling, we have to deal with different technical sides :
In this post, we will focus on execution time because i faced some scenario where i had to deal with big size of data which were resulting in too much execution time. Now let imagine a flow which loads 50 millions of sql rows from one database and has to store them into another : the process has to insert or update data in the target database. Depending on how the flow is designed, execution time can be completely different (from days to a few hours).
For our first case, let suppose we only have to insert data from our source database inside the target database. That is “slighlty” the easiest part of our flow as SSIS provides us ready to use tools. To achieve that, first, add a data flow task which contains an OLE DB Source. Configure your SSIS connection and choose a “table or view” access mode. From there, i always specify only the columns which i need in my process. Use the column tab of your source to do aswell :
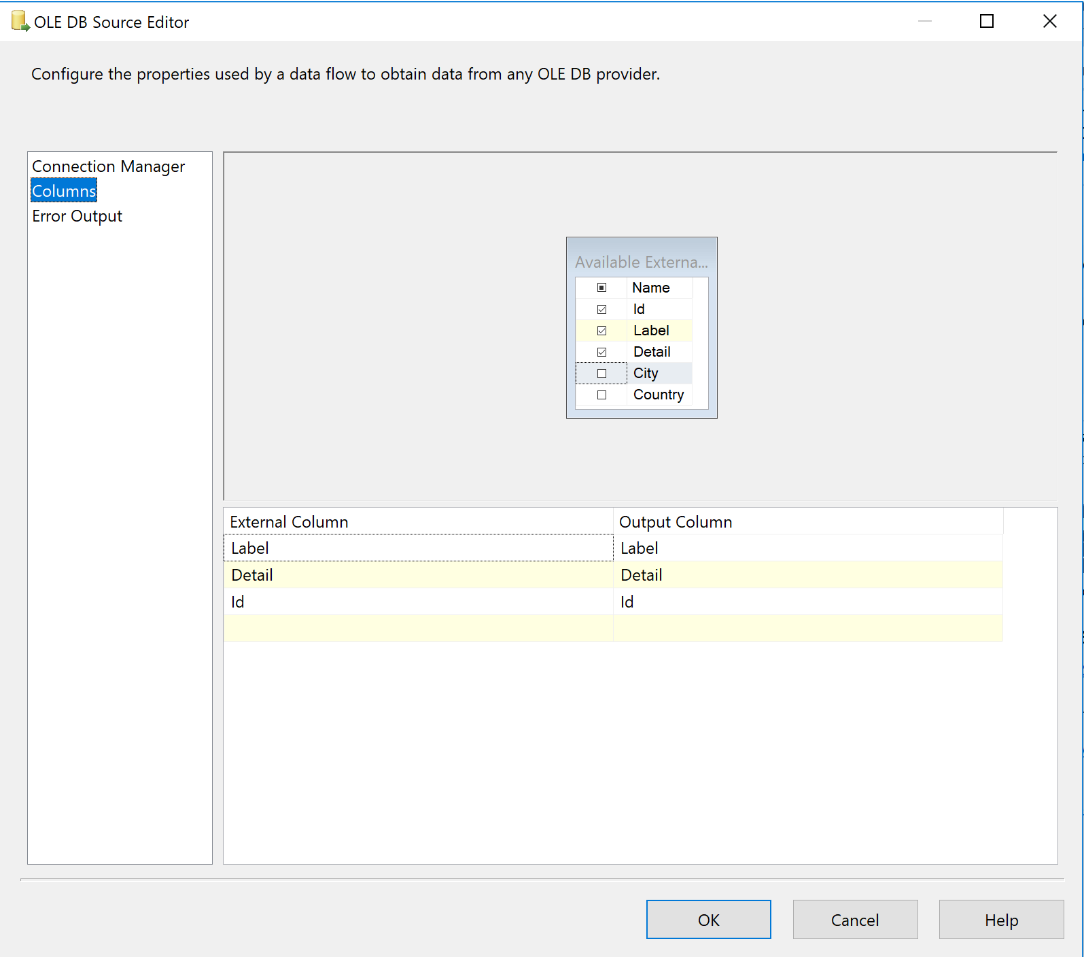
Now your source component is fully configured. Then add a simple OLE DB Destination component to define your target process. At this step, you should consider following options :
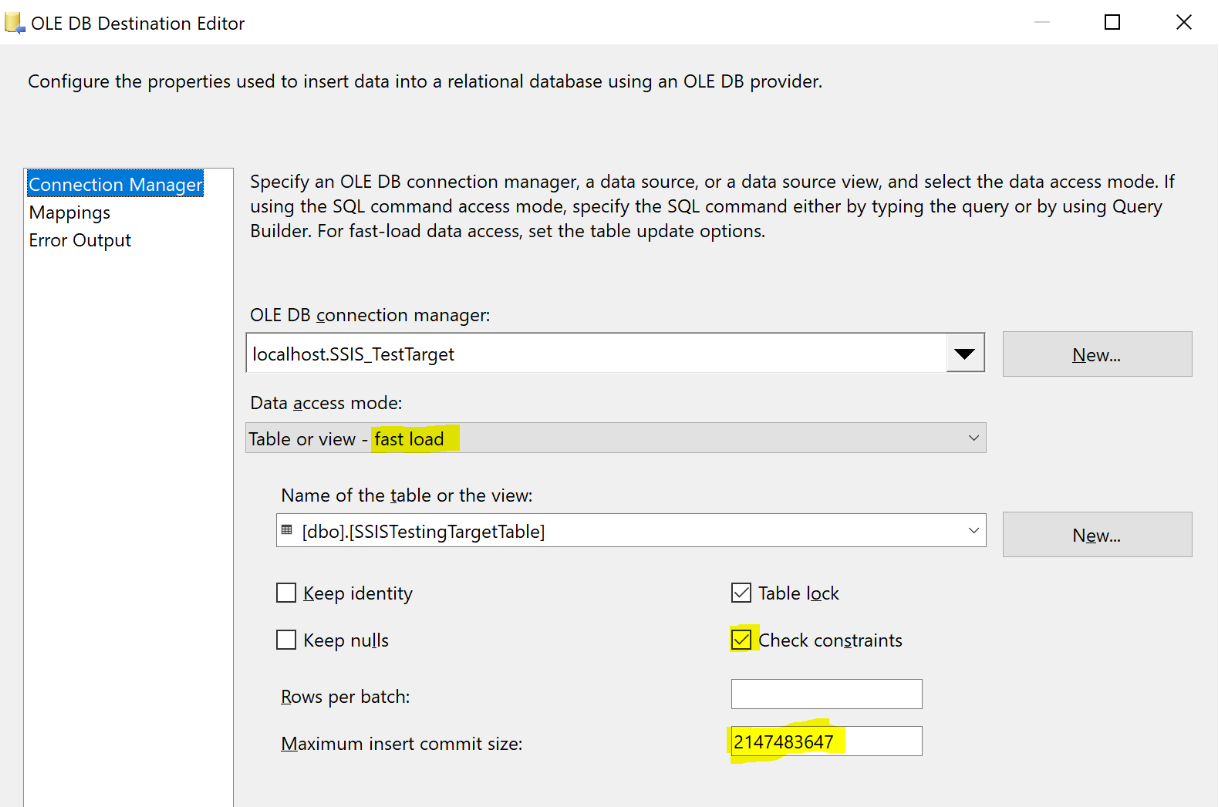
These are the minimum properties available in SSIS you should worry about while managing a simple insert process.
Of course, you should mapping your source and target columns to insert data wherever you want.
Even if SSIS does awesome job while sending data by inserting them, it’s not clearly designed to make a bunch of update requests. So, if you have a lot of data to update, you should avoid using SQL Command inside a OLE DB Destination target component. It will clearly take too much time to process and it’s today seen as a bad design behavior. Using SSIS, it’s admitted the best design for these kind of processes is to use stagging table. Shortly :
Once data are in the stagging table of the target SQL Server database, using a stored procedure will give you the way to do a bulk commit for all your updates. There is no chance you can easily achieve that goal directly inside your SSIS package.
You probably thinking that bulk inserts either updates are making it hard to monitor which data has been inserted or updated. Indeed it does. It’s an all or nothing approach. You can consider to configure a limit to your batch queries when you are manipulating data (for instance define a lower maximum commit insert size on fast load inserts) but it all depends on your needs.