Whether working in project mode or in a “Service Center” style integration team, it very often happens that the end of a sprint is reached with some tasks incomplete.
According to the Agile methodology and its various frameworks (Scrum being the most popular), such situations are obviously to be avoided as much as possible.
However, we all know that our job is all about adapting to various changes, sometimes even mid-sprint.
New high priority requests, the dropping of requirements or assigning a lower priority and so on are par for the course in integration work.
We have been using Azure DevOps (the new name for VSTS) for several years now and we generally organize our teams and projects with the Agile methodology. Hence, we now have enough experience to step back and note the following:
“Agile methodology (and by extension the Azure DevOps system) needs to adapt to our organization, not the other way round.”
Taking this observation as the start point, how can incomplete tasks be better managed in Azure DevOps at the end of a sprint?
What we can call “sprint splitting” can be done manually, but we strongly recommend putting a procedure in place.
Many aspects can be automated, or made far easier, by the TFS Excel (and consequently Access) plugin. These aspects will form the subject of another article.
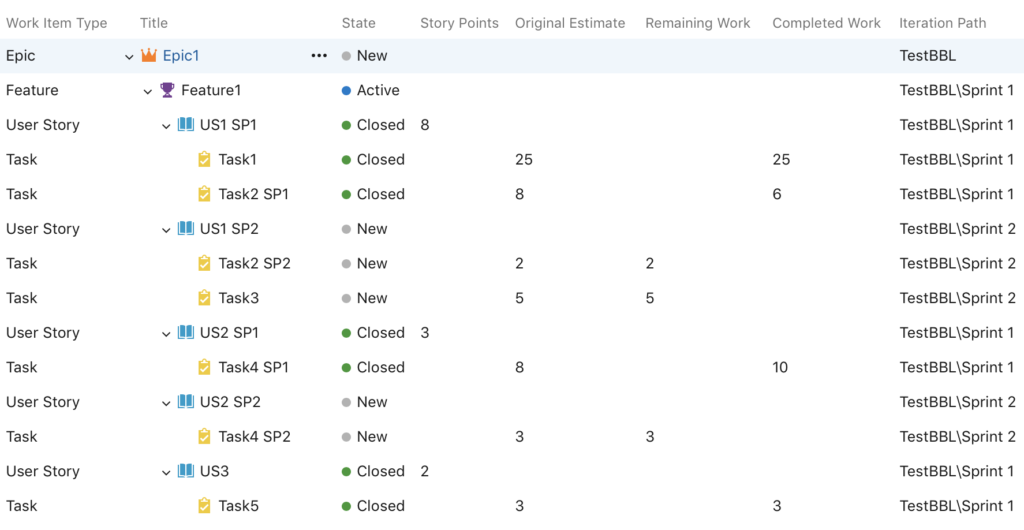
Let’s cut to the chase. The screen image below shows the backlog at the end of sprint 1.

It can be clearly seen that tasks 2, 3 and 4 are not complete.
Shifting the product backlog items from sprint 1 to sprint 2 is most definitely not the answer.
In so doing, the effort applied to the velocity for sprint 1 will be shifted to the effort in sprint 2. For example, take US1 where the estimated effort is 13. Here, 31 hours have already been completed, leaving just 7. If you shift this whole user story to the following sprint, the velocity for sprint 1 will no longer accurately represent the effort accomplished for the current sprint. In addition, the effort of 13 that will be applied to sprint 2 will no longer really mean much, as very few hours will actually remain.
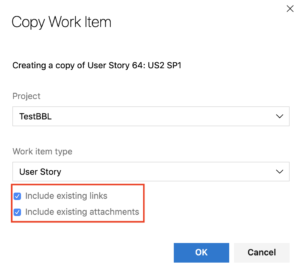
The following shows how sprint splitting is handled:

When duplicating items, remember to include existing links (see below):
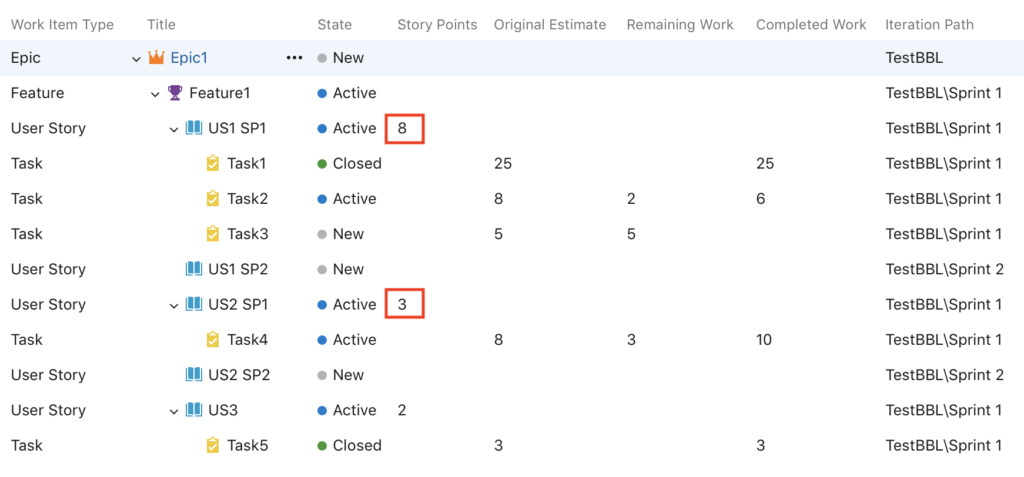
As can be seen, we have renamed the user stories for the sake of greater clarity.
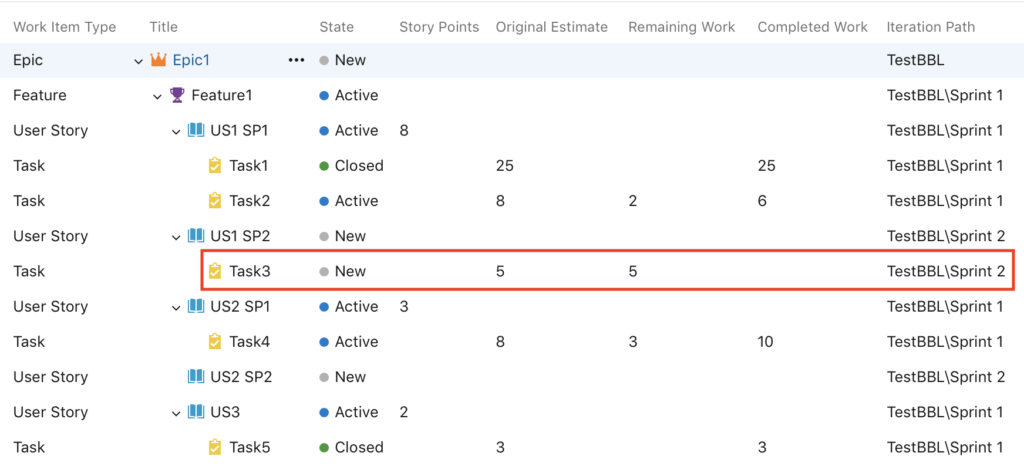
In our example, only task 3 is affected.
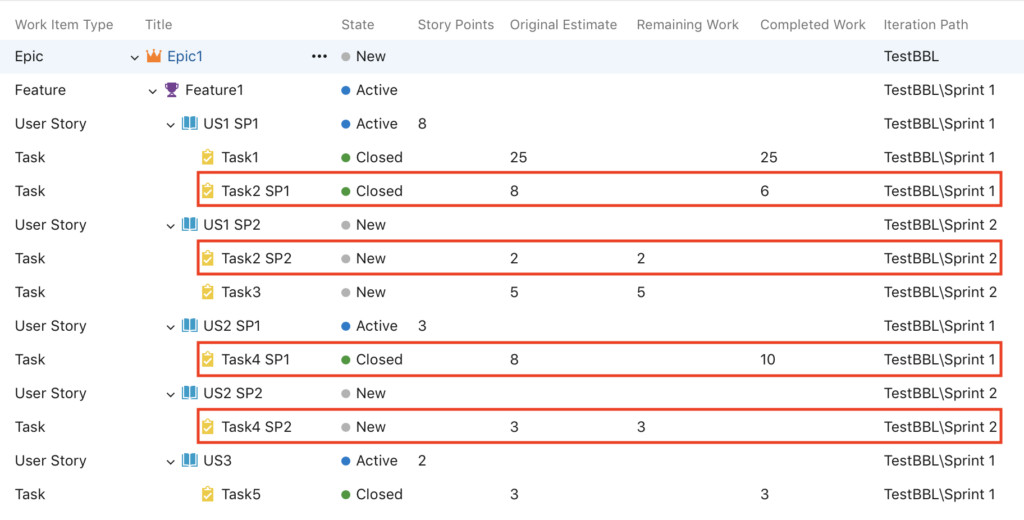
In our example, this concerns tasks 2 and 4.
As you can see, this job could quickly become tedious if you have a large number of incomplete tasks. Hence you are encouraged to automate as much of the process as possible.
Despite this somewhat tedious aspect, you will see that there are many benefits to adopting this approach:
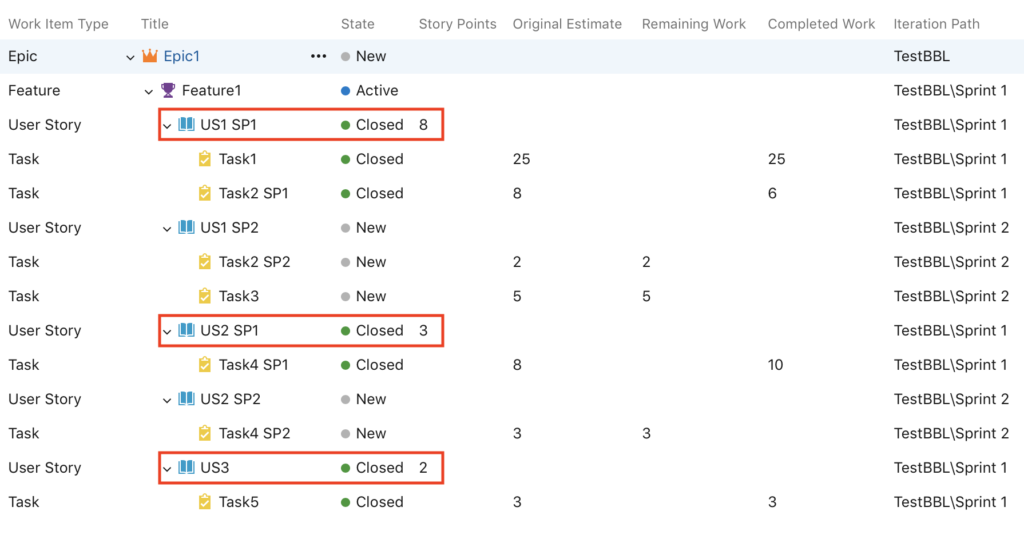
To close this article, an image of the backlog before and after the “sprint splitting” is shown below:
Before:
After :