
One issue I often encounter within BizTalk projects is aggregating and assembling flat files. While mechanisms do exist to carry out both operations, the most important thing is still to know when and how an aggregation should be closed.
It is true that orchestration is the order of the day in our situation, and using it means we can manage the time allowed for each aggregation. For more info, see the following article: Aggregating messages in an orchestration with a send pipeline.
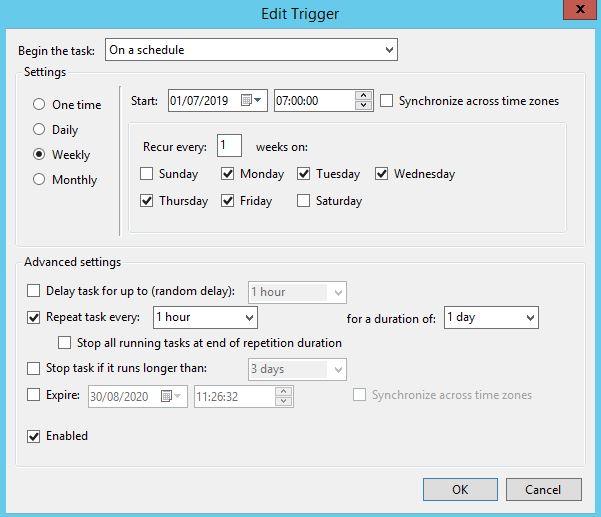
However, if it is intended to schedule aggregation closedown on the basis of the day of the week and time of day, the scheduling functionalities offered by the receive ports must also be used. That can be somewhat impractical when the timeframe and occurrence are to be changed, as it needs to be done in two difference places.
This is why, to centralize the scheduler, I am going to suggest an alternative solution using the Windows Task Scheduler.
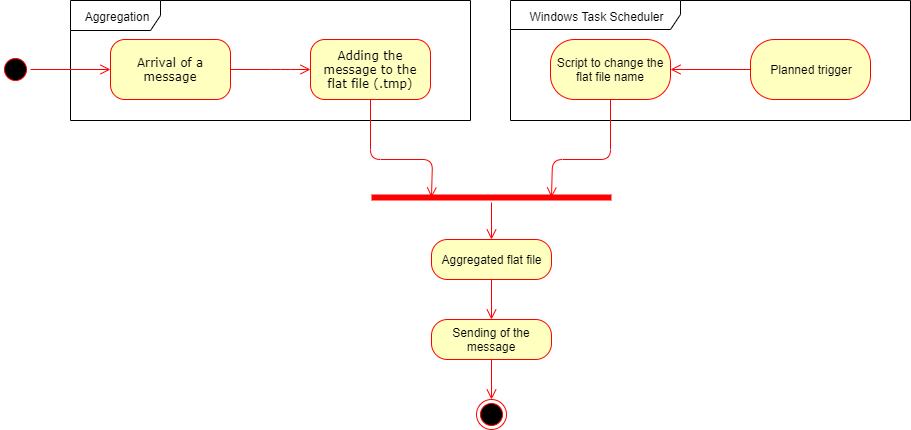
The diagram below shows how the process works:
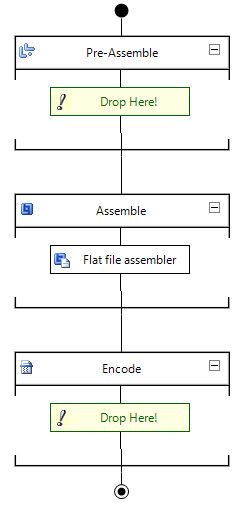
First of all, we need a pipeline containing a Flat File Assembler. This pipeline will be used to aggregate messages in the form of a flat output file.
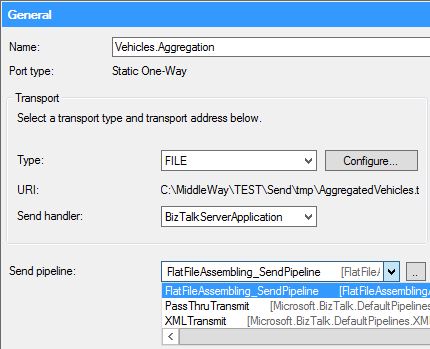
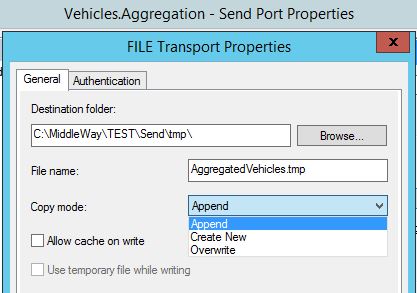
On the BizTalk side, for the sake of keeping the flow simple, we are going to use the example of “Vehicle” messages. This requires at least four ports:


Using the Windows Task Scheduler, we trigger an extension-changer script to rename the temporary file inside which the messages were aggregated. The trick is to manipulate the filename formats. In practical terms, whenever a filename ends in .csv and stops being a .tmp file, this indicates that the aggregation has finished and that, consequently, the file is ready to be processed.

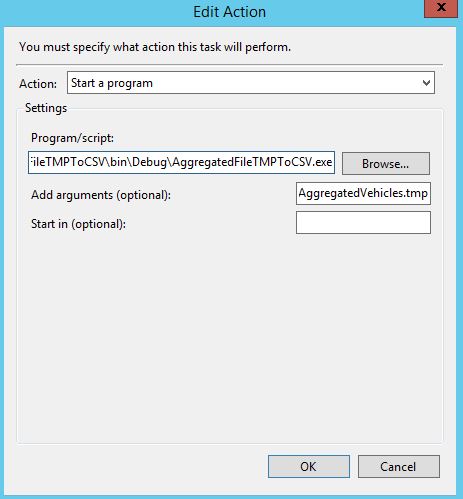
This, then, is our script to change file extensions:
namespace AggregatedFileTMPToCSV {
class Program {
static void Main(string[] args) {
// First parameter : the path
var directory = args[0];
// Second parameter : the temporary file name
var filename = args[1];
// Checking the existence of the file
if (File.Exists(Path.Combine(directory, filename))) {
try {
// Getting the temporary file
var file = Directory.GetFiles(directory, filename).First();
// Changing the extension
var newFileName = Path.ChangeExtension(file, ".csv");
// Replacement of the file
File.Move(file, newFileName);
} catch (Exception ex)
{ throw ex; }
}
}
}
}
Once everything is in place, a test can be run with the following six files, representing different vehicle messages.
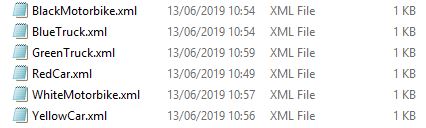
With BlackMotorBike.xml, such as:
<ns0:Vehicle xmlns:ns0="http://MiddleWay.Blogs.Biztalk.FlatFileAssemblingAfterAggregation.Vehicles.Vehicle_Schema"> <ns0:id>2</ns0:id> <ns0:type>Motorbike</ns0:type> <ns0:color>Black</ns0:color> <ns0:numberOfSeats>1</ns0:numberOfSeats> <ns0:numberOfWheels>2</ns0:numberOfWheels> </ns0:Vehicle>
After triggering our flow, the temporary file is created:
![]()
When the scheduler runs the script, the filename is changed and does in fact hold data for each vehicle:
![]()
| 2 | Motorbike | Black | 1 | 2 |
| 3 | Truck | Blue | 3 | 10 |
| 6 | Truck | Green | 3 | 10 |
| 1 | Car | Red | 5 | 4 |
| 5 | Motorbike | White | 1 | 2 |
| 4 | Car | Yellow | 5 | 4 |
In addition, for one of my projects, I needed to separate the message aggregation on the basis of the value in a given field. So, let’s look at the previous example again, highlighting the desired field. Here, we will use the “type” field.
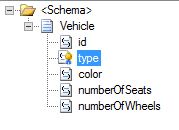
We append our new send ports including a filter on “type” in order to retrieve only the vehicles we want.


Lastly, if we want to process each vehicle type separately, we can re-use our script without changing anything. We can consequently just schedule new tasks for each type.

Before our scheduler triggers processing, the different files can be seen in the middle of the aggregation operation.
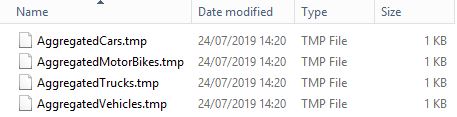
Once our script has been run, our flat files are finally ready to be sent.
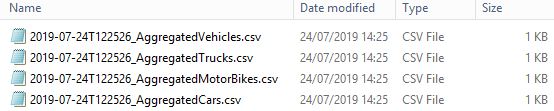
With for example […]_AgregatedCars.csv, which holds only ‘Motorbike’ [sic] type data:
| 1 | Car | Red | 5 | 4 |
| 4 | Car | Yellow | 5 | 4 |